Refine search
Actions for selected content:
53194 results in Statistics and Probability
Chapter Eighteen - Non-parametric Methods
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 626-659
-
- Chapter
- Export citation
3 - Estimation and Decision-Making
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp 73-120
-
- Chapter
- Export citation
Appendices
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 707-745
-
- Chapter
- Export citation
On minimum spanning trees for random Euclidean bipartite graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 30 November 2023, pp. 319-350
-
- Article
- Export citation
-
We consider the minimum spanning tree problem on a weighted complete bipartite graph
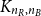 $K_{n_R, n_B}$ whose
$K_{n_R, n_B}$ whose 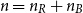 $n=n_R+n_B$ vertices are random, i.i.d. uniformly distributed points in the unit cube in
$n=n_R+n_B$ vertices are random, i.i.d. uniformly distributed points in the unit cube in 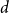 $d$ dimensions and edge weights are the
$d$ dimensions and edge weights are the 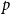 $p$-th power of their Euclidean distance, with
$p$-th power of their Euclidean distance, with 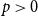 $p\gt 0$. In the large
$p\gt 0$. In the large  $n$ limit with
$n$ limit with 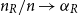 $n_R/n \to \alpha _R$ and
$n_R/n \to \alpha _R$ and 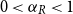 $0\lt \alpha _R\lt 1$, we show that the maximum vertex degree of the tree grows logarithmically, in contrast with the classical, non-bipartite, case, where a uniform bound holds depending on
$0\lt \alpha _R\lt 1$, we show that the maximum vertex degree of the tree grows logarithmically, in contrast with the classical, non-bipartite, case, where a uniform bound holds depending on 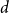 $d$ only. Despite this difference, for
$d$ only. Despite this difference, for 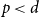 $p\lt d$, we are able to prove that the total edge costs normalized by the rate
$p\lt d$, we are able to prove that the total edge costs normalized by the rate 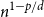 $n^{1-p/d}$ converge to a limiting constant that can be represented as a series of integrals, thus extending a classical result of Avram and Bertsimas to the bipartite case and confirming a conjecture of Riva, Caracciolo and Malatesta.
$n^{1-p/d}$ converge to a limiting constant that can be represented as a series of integrals, thus extending a classical result of Avram and Bertsimas to the bipartite case and confirming a conjecture of Riva, Caracciolo and Malatesta.
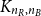
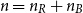
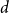
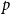
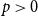

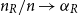
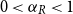
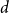
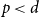
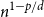
8 - Spectral Analysis of Time Series
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp 287-328
-
- Chapter
- Export citation
Preface
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp xv-xviii
-
- Chapter
- Export citation
6 - Covariance Matrices, EOFs, and PCs
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp 200-242
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp xix-xx
-
- Chapter
- Export citation
Chapter Four - Re-expressing Variables
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 119-158
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp xix-xix
-
- Chapter
- Export citation
Chapter Ten - Inferences Involving the Mean of a Single Population when σ is Known
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 294-321
-
- Chapter
- Export citation
1 - Basics of Climate Data Arrays, Statistics, and Visualization
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp 1-34
-
- Chapter
-
- You have access
- Export citation
Chapter Nineteen - Customizing and Exporting Tables to Microsoft Word and Excel Using the New Table Command
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 660-691
-
- Chapter
- Export citation
Dynamics of information networks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 30 November 2023, pp. 1029-1039
- Print publication:
- September 2024
-
- Article
- Export citation
Chapter Thirteen - One-Way Analysis of Variance
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 416-460
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp iv-iv
-
- Chapter
- Export citation
Chapter Fifteen - Correlation and Simple Regression as Inferential Techniques
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 507-556
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp i-iv
-
- Chapter
- Export citation
Chapter Fourteen - Two-Way Analysis of Variance
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 461-506
-
- Chapter
- Export citation
References
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 746-749
-
- Chapter
- Export citation
