Refine search
Actions for selected content:
53192 results in Statistics and Probability
Copyright page
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp iv-iv
-
- Chapter
- Export citation
Index
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 693-704
-
- Chapter
- Export citation
Chapter Three - Measures of Location, Spread, and Skewness
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 72-109
-
- Chapter
- Export citation
Chapter Nineteen - Accessing Data from Public-Use Sources
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 627-649
-
- Chapter
- Export citation
Contents
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp vii-xiv
-
- Chapter
- Export citation
Appendix C - Statistical Tables
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 666-687
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp xix-xx
-
- Chapter
- Export citation
Chapter Thirteen - One-Way Analysis of Variance
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 401-438
-
- Chapter
- Export citation
Product structure of graph classes with bounded treewidth
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 07 December 2023, pp. 351-376
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that many graphs with bounded treewidth can be described as subgraphs of the strong product of a graph with smaller treewidth and a bounded-size complete graph. To this end, define the underlying treewidth of a graph class
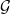 $\mathcal{G}$ to be the minimum non-negative integer
$\mathcal{G}$ to be the minimum non-negative integer  $c$ such that, for some function
$c$ such that, for some function 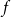 $f$, for every graph
$f$, for every graph 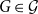 $G \in \mathcal{G}$ there is a graph
$G \in \mathcal{G}$ there is a graph 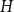 $H$ with
$H$ with 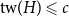 $\textrm{tw}(H) \leqslant c$ such that
$\textrm{tw}(H) \leqslant c$ such that 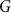 $G$ is isomorphic to a subgraph of
$G$ is isomorphic to a subgraph of 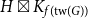 $H \boxtimes K_{f(\textrm{tw}(G))}$. We introduce disjointed coverings of graphs and show they determine the underlying treewidth of any graph class. Using this result, we prove that the class of planar graphs has underlying treewidth
$H \boxtimes K_{f(\textrm{tw}(G))}$. We introduce disjointed coverings of graphs and show they determine the underlying treewidth of any graph class. Using this result, we prove that the class of planar graphs has underlying treewidth 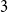 $3$; the class of
$3$; the class of 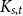 $K_{s,t}$-minor-free graphs has underlying treewidth
$K_{s,t}$-minor-free graphs has underlying treewidth  $s$ (for
$s$ (for 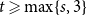 $t \geqslant \max \{s,3\}$); and the class of
$t \geqslant \max \{s,3\}$); and the class of 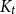 $K_t$-minor-free graphs has underlying treewidth
$K_t$-minor-free graphs has underlying treewidth  $t-2$. In general, we prove that a monotone class has bounded underlying treewidth if and only if it excludes some fixed topological minor. We also study the underlying treewidth of graph classes defined by an excluded subgraph or excluded induced subgraph. We show that the class of graphs with no
$t-2$. In general, we prove that a monotone class has bounded underlying treewidth if and only if it excludes some fixed topological minor. We also study the underlying treewidth of graph classes defined by an excluded subgraph or excluded induced subgraph. We show that the class of graphs with no 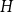 $H$ subgraph has bounded underlying treewidth if and only if every component of
$H$ subgraph has bounded underlying treewidth if and only if every component of 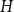 $H$ is a subdivided star, and that the class of graphs with no induced
$H$ is a subdivided star, and that the class of graphs with no induced 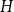 $H$ subgraph has bounded underlying treewidth if and only if every component of
$H$ subgraph has bounded underlying treewidth if and only if every component of 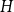 $H$ is a star.
$H$ is a star.

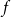
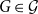
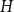
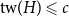
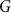
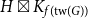
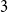
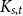

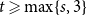
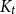

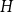
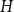
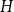
Chapter Sixteen - An Introduction To Multiple Regression
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 533-567
-
- Chapter
- Export citation
Chapter Eight - Theoretical Probability Models
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 243-269
-
- Chapter
- Export citation
Chapter Eighteen - Nonparametric Methods
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 595-626
-
- Chapter
- Export citation
Chapter Fourteen - Two-Way Analysis of Variance
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 439-483
-
- Chapter
- Export citation
Chapter Five - Exploring Relationships between Two Variables
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 148-194
-
- Chapter
- Export citation
Appendix B - .R Files and Datasets in R Format
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 665-665
-
- Chapter
- Export citation
Appendix D - Solutions TO END-OF-CHAPTER EXERCISES
-
- Book:
- Statistics Using R
- Published online:
- 07 December 2023
- Print publication:
- 07 December 2023, pp 688-688
-
- Chapter
- Export citation
ACCI could be a poor prognostic indicator for the in-hospital mortality of patients with SFTS
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 06 December 2023, e203
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Weak convergence of the extremes of branching Lévy processes with regularly varying tails
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 06 December 2023, pp. 622-643
- Print publication:
- June 2024
-
- Article
- Export citation
-
We study the weak convergence of the extremes of supercritical branching Lévy processes
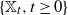 $\{\mathbb{X}_t, t \ge0\}$ whose spatial motions are Lévy processes with regularly varying tails. The result is drastically different from the case of branching Brownian motions. We prove that, when properly renormalized,
$\{\mathbb{X}_t, t \ge0\}$ whose spatial motions are Lévy processes with regularly varying tails. The result is drastically different from the case of branching Brownian motions. We prove that, when properly renormalized, 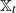 $\mathbb{X}_t$ converges weakly. As a consequence, we obtain a limit theorem for the order statistics of
$\mathbb{X}_t$ converges weakly. As a consequence, we obtain a limit theorem for the order statistics of 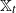 $\mathbb{X}_t$.
$\mathbb{X}_t$.
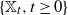
High prevalence of asymptomatic malaria in Forest Guinea: Results from a rapid community survey
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 05 December 2023, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of a SARIMA-XGBoost model for hand, foot, and mouth disease in Xinjiang, China
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 04 December 2023, e200
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
