Refine search
Actions for selected content:
42 results
Mixed data-source transfer learning for a turbulence model augmented physics-informed neural network
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 10 July 2026, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Physics-informed neural networks (PINNs) are a promising alternative for extracting additional time-averaged (mean) flow quantities from experimental data. In the case of particle image velocimetry (PIV), for example, the measured mean flow field is contaminated by noise, has a limited field of view, is restricted to a uniform grid, and does not provide the pressure field. To overcome these limitations, we present a methodology in which PINNs are first trained on a Reynolds-averaged Navier–Stokes (RANS) simulation such that it learns all states at every location in the domain. We then apply transfer learning, which updates the PINN using sub-sampled PIV data. The resulting predictions are in significantly better agreement with the full PIV dataset than PINNs, which are trained on experimental data only. This work builds on the recent literature by integrating a Spalart-Allmaras turbulence model and applying hard constraints to the no-slip wall boundary condition. We apply this methodology to a two-dimensional NACA 0012 airfoil inclined at an angle of attack, $ \alpha $
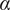 = 15°, for two Reynolds numbers of Re = 10,000 and 75,000. The proposed methodology is initially validated using large eddy simulation (LES) data and then demonstrated on experimental PIV data. Our transfer learning approach results in improved predictions and a reduction in training time when compared to using a random network initialization.
= 15°, for two Reynolds numbers of Re = 10,000 and 75,000. The proposed methodology is initially validated using large eddy simulation (LES) data and then demonstrated on experimental PIV data. Our transfer learning approach results in improved predictions and a reduction in training time when compared to using a random network initialization.
Toward transferable models for efficient spatiotemporal flood prediction across coastal-estuarine systems
-
- Journal:
- Cambridge Prisms: Coastal Futures / Volume 4 / 2026
- Published online by Cambridge University Press:
- 04 June 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transfer learning in hard landing risk prediction
-
- Journal:
- The Aeronautical Journal / Volume 130 / Issue 1349 / July 2026
- Published online by Cambridge University Press:
- 21 May 2026, pp. 2080-2107
-
- Article
- Export citation
Maghrebi dialects – Arabic bidirectional translation: an improved transformer with transfer learning
-
- Journal:
- Natural Language Processing / Volume 32 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 10 March 2026, pp. 204-223
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Can time-series foundation models perform building energy management tasks?
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 02 March 2026, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Measuring inter-party communication: a transformer-based approach
-
- Journal:
- Political Science Research and Methods , First View
- Published online by Cambridge University Press:
- 24 February 2026, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
21 - Large Language Models
- from Part VII - Large Language Models
-
- Book:
- Introduction to Machine Learning
- Published online:
- 05 February 2026
- Print publication:
- 18 December 2025, pp 523-553
-
- Chapter
- Export citation
What KAN mortality say: smooth and interpretable mortality modeling using Kolmogorov−Arnold networks
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 28 November 2025, pp. 32-59
- Print publication:
- January 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predictive monitoring of asset populations in a rotating plant under operational uncertainty: a transfer learning approach
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 17 March 2025, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Time series predictions in unmonitored sites: a survey of machine learning techniques in water resources
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 22 January 2025, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data-driven multifidelity surrogate models for rocket engines injector design
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 08 January 2025, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Meta-models for transfer learning in source localization
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 27 December 2024, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transfer learning for predicting source terms of principal component transport in chemically reactive flow
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 13 December 2024, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Flexible multi-fidelity framework for load estimation of wind farms through graph neural networks and transfer learning
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 12 November 2024, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiple yield curve modeling and forecasting using deep learning
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 04 October 2024, pp. 463-494
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Intraday residual transfer learning in minimally observed power distribution networks dynamic state estimation
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 08 May 2024, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Empirical evidence and computational assessment on design knowledge transferability
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 12 April 2024, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
