Refine search
Actions for selected content:
101325 results in Language and Linguistics
Part II - Theories, Key Concepts and Approaches
-
- Book:
- Introducing Environmental Communication
- Published online:
- 29 April 2026
- Print publication:
- 14 May 2026, pp 65-200
-
- Chapter
- Export citation
5 - The Riddle of “DL”
-
- Book:
- Language Rules!
- Published online:
- 14 May 2026
- Print publication:
- 14 May 2026, pp 88-111
-
- Chapter
- Export citation
Preface
-
- Book:
- Words that Wound
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp xiii-xiv
-
- Chapter
- Export citation
2 - Understanding Offence
-
- Book:
- Words that Wound
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp 27-55
-
- Chapter
- Export citation
9 - Conclusion
-
- Book:
- Words that Wound
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp 174-177
-
- Chapter
- Export citation
8 - Sociological Approaches
- from Part II - Theories, Key Concepts and Approaches
-
- Book:
- Introducing Environmental Communication
- Published online:
- 29 April 2026
- Print publication:
- 14 May 2026, pp 149-166
-
- Chapter
- Export citation
5 - Semantic Domains of Offensive Language
-
- Book:
- Words that Wound
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp 91-106
-
- Chapter
- Export citation
1 - Constructing the Environment
- from Part I - Introducing Environmental Communication
-
- Book:
- Introducing Environmental Communication
- Published online:
- 29 April 2026
- Print publication:
- 14 May 2026, pp 3-27
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Languaging
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp iv-iv
-
- Chapter
- Export citation
8 - Creativity and Offence
-
- Book:
- Words that Wound
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp 151-173
-
- Chapter
- Export citation
References
-
- Book:
- Languaging
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp 158-181
-
- Chapter
- Export citation
3 - Beyond English
-
- Book:
- Language Rules!
- Published online:
- 14 May 2026
- Print publication:
- 14 May 2026, pp 42-63
-
- Chapter
- Export citation
Figures
-
- Book:
- Words that Wound
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp x-x
-
- Chapter
- Export citation
2 - First Languaging, First Knowledging
-
- Book:
- Languaging
- Published online:
- 24 April 2026
- Print publication:
- 14 May 2026, pp 35-62
-
- Chapter
- Export citation
11 - Can Apes Learn Language?
-
- Book:
- Language Rules!
- Published online:
- 14 May 2026
- Print publication:
- 14 May 2026, pp 207-229
-
- Chapter
- Export citation
Foreword by Claudia Escorza
-
- Book:
- Introducing Environmental Communication
- Published online:
- 29 April 2026
- Print publication:
- 14 May 2026, pp xix-xx
-
- Chapter
- Export citation
Input Language (English, Polish) and Monolingual and Bilingual Children’s Use of Compounding and Derivational Word-Formation Processes
-
- Journal:
- Journal of Child Language , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A representational analysis of Czech palatalisation
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We discuss three patterns of palatalisation in Czech, each of which is associated with certain suffixes. The data suggest that the trigger of palatalisation is not the initial vowel of these suffixes, but different sets of floating melodic features. We provide a formal analysis of the palatalisation patterns, as well as of the internal structure of the Czech phoneme inventory, in terms of Element Theory and strict CV. This allows us to straightforwardly model their lateral (leftward) effect, as well as some peculiar behaviour in the context of labials and the lateral
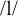 . Besides Element Theory and strict CV, we argue that this analysis provides further support to a substance-free view of phonology, in which phonological representations do not necessarily have a universal, fixed phonetic implementation.
. Besides Element Theory and strict CV, we argue that this analysis provides further support to a substance-free view of phonology, in which phonological representations do not necessarily have a universal, fixed phonetic implementation.
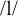 . Besides Element Theory and strict CV, we argue that this analysis provides further support to a substance-free view of phonology, in which phonological representations do not necessarily have a universal, fixed phonetic implementation.
. Besides Element Theory and strict CV, we argue that this analysis provides further support to a substance-free view of phonology, in which phonological representations do not necessarily have a universal, fixed phonetic implementation.The foreign language effect in the illusion of causality: Evidence of absence
-
- Journal:
- Bilingualism: Language and Cognition , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What impacts language learning and L2 confidence in a workplace setting? Experiences of international staff at a Norwegian university
-
- Journal:
- Nordic Journal of Linguistics , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
