Refine search
Actions for selected content:
101325 results in Language and Linguistics
Word-specific tonal realizations in Mandarin
-
- Journal:
- Language ,
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The syntax of quantifiers in Chuj
-
- Journal:
- Canadian Journal of Linguistics/Revue canadienne de linguistique , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper provides a novel description and syntactic analysis of different types of quantifiers in Chuj, an underdocumented Mayan language. We focus on a subset of expressions that quantify over entities, and that have been noted to appear obligatorily in sentence-initial position. We argue that three types of quantifiers should be distinguished: (i) Predicative A-quantifiers, which occur sentence-initially because Chuj is a predicate-initial language; (ii) Focus D-quantifiers, which occur sentence-initially because they are lexically specified for an [A
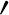 $'$] feature; and (iii) Basic D-quantifiers, which, lacking an [A
$'$] feature; and (iii) Basic D-quantifiers, which, lacking an [A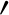 $'$] feature, have no effects on the syntactic position of their host arguments. We also sketch syntactic analyses of each type of quantifier.
$'$] feature, have no effects on the syntactic position of their host arguments. We also sketch syntactic analyses of each type of quantifier.
Bilingual language control and cognate processing: the role of proficiency, exposure, and attitudes
-
- Journal:
- Bilingualism: Language and Cognition , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cognitive performance differences between Chinese and European students in the UK: An effect of linguistic difference?
-
- Journal:
- Bilingualism: Language and Cognition , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A first exploration of word- and phrase-final f0 movements in spontaneous Yali
-
- Journal:
- Phonological Data and Analysis / Volume 8 / 2026
- Published online by Cambridge University Press:
- 13 May 2026, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Audiovisual (a)synchrony: Reading ahead as a mechanism for L2 vocabulary processing and learning benefits of reading while listening
-
- Journal:
- Studies in Second Language Acquisition , First View
- Published online by Cambridge University Press:
- 12 May 2026, pp. 1-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Messy data, low-resource languages, and LLMs: Narrative analysis of pre-modern Slavic Lives of Saints
-
- Journal:
- Computational Humanities Research / Accepted manuscript
- Published online by Cambridge University Press:
- 12 May 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- Export citation
Proceedings of the Linguistic Society of America: At the Twenty-Second Annual Meeting Yale University, New Haven, December 29–30, 1947
-
- Journal:
- Language / Volume 24 / Issue 3-Part3 / September 1948
- Published online by Cambridge University Press:
- 11 May 2026, pp. 6-19
-
- Article
- Export citation
L’im/politesse en français : Nouveaux questionnements
-
- Journal:
- Journal of French Language Studies / Volume 36 / 2026
- Published online by Cambridge University Press:
- 11 May 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using large corpus data for the reconstruction of cross-cultural concept differences: happiness and joy in West Slavic languages and in English
-
- Journal:
- Language and Cognition / Volume 18 / 2026
- Published online by Cambridge University Press:
- 11 May 2026, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
LAN volume 24 issue 3-Part3 Cover and Front matter
-
- Journal:
- Language / Volume 24 / Issue 3-Part3 / September 1948
- Published online by Cambridge University Press:
- 11 May 2026, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Le compliment dans des interactions ordinaires et des émissions télévisées – émissions de talent et talk-shows – en français
-
- Journal:
- Journal of French Language Studies / Volume 36 / 2026
- Published online by Cambridge University Press:
- 11 May 2026, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Subject gaps in coordination at the syntax-pragmatics interface
-
- Journal:
- Journal of Linguistics , First View
- Published online by Cambridge University Press:
- 11 May 2026, pp. 1-33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Do heritage speakers work harder in their heritage language? A dual task study of cognitive effort in bilingual language processing
-
- Journal:
- Bilingualism: Language and Cognition , First View
- Published online by Cambridge University Press:
- 11 May 2026, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Disentangling the causal role of motivation, enjoyment, and anxiety in second language speech learning: A final report – CORRIGENDUM
-
- Journal:
- Studies in Second Language Acquisition , First View
- Published online by Cambridge University Press:
- 11 May 2026, p. 1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
List of Members 1947
-
- Journal:
- Language / Volume 24 / Issue 3-Part3 / September 1948
- Published online by Cambridge University Press:
- 11 May 2026, pp. 20-55
-
- Article
- Export citation
The role of pitch accent in Vedic Sanskrit poetics
-
- Journal:
- Phonological Data and Analysis / Volume 8 / 2026
- Published online by Cambridge University Press:
- 11 May 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Proceedings of the Linguistic Society of America: At the Ninth Summer Meeting Ann Arbor, Michigan, August 1–2, 1947
-
- Journal:
- Language / Volume 24 / Issue 3-Part3 / September 1948
- Published online by Cambridge University Press:
- 11 May 2026, pp. 3-5
-
- Article
- Export citation
Jacques Durand et Chantal Lyche, Paul Passy, un linguiste révolutionnaire. Fribourg: Lambert-Lucas, 2024, 400 pp., ISBN: 978-2-35935-441-6.
-
- Journal:
- Journal of French Language Studies / Volume 36 / 2026
- Published online by Cambridge University Press:
- 11 May 2026, e15
-
- Article
- Export citation
Feeling clean: Language materiality and the discursive production of value in hotel ‘laundry routes’ – ERRATUM
-
- Journal:
- Language in Society , First View
- Published online by Cambridge University Press:
- 11 May 2026, p. 1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
