Refine listing
Actions for selected content:
262 results in 15xxx
Efficient Preconditioner and Iterative Method for Large Complex Symmetric Linear Algebraic Systems
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 7 / Issue 3 / August 2017
- Published online by Cambridge University Press:
- 07 September 2017, pp. 530-547
- Print publication:
- August 2017
-
- Article
- Export citation
Analysis of Hexagonal Grid Finite Difference Methods for Anisotropic Laplacian Related Equations
- Part of
-
- Journal:
- Numerical Mathematics: Theory, Methods and Applications / Volume 10 / Issue 3 / August 2017
- Published online by Cambridge University Press:
- 20 June 2017, pp. 562-596
- Print publication:
- August 2017
-
- Article
- Export citation
Numerical Ranges in II1 Factors
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 61 / Issue 1 / February 2018
- Published online by Cambridge University Press:
- 16 March 2017, pp. 31-55
-
- Article
- Export citation
The Disc Theorem for the Schur Complement of Two Class Submatrices with γ-Diagonally Dominant Properties
- Part of
-
- Journal:
- Numerical Mathematics: Theory, Methods and Applications / Volume 10 / Issue 1 / February 2017
- Published online by Cambridge University Press:
- 20 February 2017, pp. 84-97
- Print publication:
- February 2017
-
- Article
- Export citation
The Explicit Inverses of CUPL-Toeplitz and CUPL-Hankel Matrices
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 7 / Issue 1 / February 2017
- Published online by Cambridge University Press:
- 31 January 2017, pp. 38-54
- Print publication:
- February 2017
-
- Article
- Export citation
SOR-like Methods with Optimization Model for Augmented Linear Systems
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 7 / Issue 1 / February 2017
- Published online by Cambridge University Press:
- 31 January 2017, pp. 101-115
- Print publication:
- February 2017
-
- Article
- Export citation
A Filtered-Davidson Method for Large Symmetric Eigenvalue Problems
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 7 / Issue 1 / February 2017
- Published online by Cambridge University Press:
- 31 January 2017, pp. 21-37
- Print publication:
- February 2017
-
- Article
- Export citation
Convergence Rates of a Class of Predictor-Corrector Iterations for the Nonsymmetric Algebraic Riccati Equation Arising in Transport Theory
- Part of
-
- Journal:
- Advances in Applied Mathematics and Mechanics / Volume 9 / Issue 4 / August 2017
- Published online by Cambridge University Press:
- 18 January 2017, pp. 944-963
- Print publication:
- August 2017
-
- Article
- Export citation
A Robust and Efficient Adaptive Multigrid Solver for the Optimal Control of Phase Field Formulations of Geometric Evolution Laws
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 21 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 05 December 2016, pp. 65-92
- Print publication:
- January 2017
-
- Article
- Export citation
OPERATOR QUASILINEARITY OF SOME FUNCTIONALS ASSOCIATED WITH DAVIS–CHOI–JENSEN’S INEQUALITY FOR POSITIVE MAPS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 95 / Issue 2 / April 2017
- Published online by Cambridge University Press:
- 19 October 2016, pp. 322-332
- Print publication:
- April 2017
-
- Article
-
- You have access
- Export citation
DASHMM: Dynamic Adaptive System for Hierarchical Multipole Methods
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 20 / Issue 4 / October 2016
- Published online by Cambridge University Press:
- 05 October 2016, pp. 1106-1126
- Print publication:
- October 2016
-
- Article
- Export citation
SOME INEQUALITIES FOR THE NUMERICAL RADIUS FOR HILBERT SPACE OPERATORS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 94 / Issue 3 / December 2016
- Published online by Cambridge University Press:
- 26 September 2016, pp. 489-496
- Print publication:
- December 2016
-
- Article
-
- You have access
- Export citation
-
We introduce some new refinements of numerical radius inequalities for Hilbert space invertible operators. More precisely, we prove that if
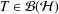 $T\in {\mathcal{B}}({\mathcal{H}})$ is an invertible operator, then
$T\in {\mathcal{B}}({\mathcal{H}})$ is an invertible operator, then 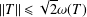 $\Vert T\Vert \leq \sqrt{2}\unicode[STIX]{x1D714}(T)$ .
$\Vert T\Vert \leq \sqrt{2}\unicode[STIX]{x1D714}(T)$ .
EXT-FINITE MODULES FOR WEAKLY SYMMETRIC ALGEBRAS WITH RADICAL CUBE ZERO
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 102 / Issue 1 / February 2017
- Published online by Cambridge University Press:
- 19 September 2016, pp. 108-121
- Print publication:
- February 2017
-
- Article
-
- You have access
- Export citation
-
Assume that
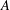 $A$ is a finite-dimensional algebra over some field, and assume that
$A$ is a finite-dimensional algebra over some field, and assume that 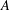 $A$ is weakly symmetric and indecomposable, with radical cube zero and radical square nonzero. We show that such an algebra of wild representation type does not have a nonprojective module
$A$ is weakly symmetric and indecomposable, with radical cube zero and radical square nonzero. We show that such an algebra of wild representation type does not have a nonprojective module 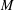 $M$ whose ext-algebra is finite dimensional. This gives a complete classification of weakly symmetric indecomposable algebras which have a nonprojective module whose ext-algebra is finite dimensional. This shows in particular that existence of ext-finite nonprojective modules is not equivalent with the failure of the finite generation condition (Fg), which ensures that modules have support varieties.
$M$ whose ext-algebra is finite dimensional. This gives a complete classification of weakly symmetric indecomposable algebras which have a nonprojective module whose ext-algebra is finite dimensional. This shows in particular that existence of ext-finite nonprojective modules is not equivalent with the failure of the finite generation condition (Fg), which ensures that modules have support varieties.
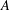
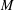
A MODIFIED FR CONJUGATE GRADIENT METHOD FOR COMPUTING
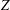 $Z$ -EIGENPAIRS OF SYMMETRIC TENSORS
$Z$ -EIGENPAIRS OF SYMMETRIC TENSORS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 94 / Issue 3 / December 2016
- Published online by Cambridge University Press:
- 26 July 2016, pp. 411-420
- Print publication:
- December 2016
-
- Article
-
- You have access
- Export citation
-
This paper proposes improvements to the modified Fletcher–Reeves conjugate gradient method (FR-CGM) for computing
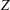 $Z$ -eigenpairs of symmetric tensors. The FR-CGM does not need to compute the exact gradient and Jacobian. The global convergence of this method is established. We also test other conjugate gradient methods such as the modified Polak–Ribière–Polyak conjugate gradient method (PRP-CGM) and shifted power method (SS-HOPM). Numerical experiments of FR-CGM, PRP-CGM and SS-HOPM show the efficiency of the proposed method for finding
$Z$ -eigenpairs of symmetric tensors. The FR-CGM does not need to compute the exact gradient and Jacobian. The global convergence of this method is established. We also test other conjugate gradient methods such as the modified Polak–Ribière–Polyak conjugate gradient method (PRP-CGM) and shifted power method (SS-HOPM). Numerical experiments of FR-CGM, PRP-CGM and SS-HOPM show the efficiency of the proposed method for finding 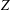 $Z$ -eigenpairs of symmetric tensors.
$Z$ -eigenpairs of symmetric tensors.
RECFMM: Recursive Parallelization of the Adaptive Fast Multipole Method for Coulomb and Screened Coulomb Interactions
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 20 / Issue 2 / August 2016
- Published online by Cambridge University Press:
- 21 July 2016, pp. 534-550
- Print publication:
- August 2016
-
- Article
- Export citation
Convergence of an Anisotropic Perfectly Matched Layer Method for Helmholtz Scattering Problems
- Part of
-
- Journal:
- Numerical Mathematics: Theory, Methods and Applications / Volume 9 / Issue 3 / August 2016
- Published online by Cambridge University Press:
- 20 July 2016, pp. 358-382
- Print publication:
- August 2016
-
- Article
- Export citation
A Block Diagonal Preconditioner for Generalised Saddle Point Problems
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 6 / Issue 3 / August 2016
- Published online by Cambridge University Press:
- 20 July 2016, pp. 235-252
- Print publication:
- August 2016
-
- Article
- Export citation
Jacobi Spectral Collocation Method for the Time Variable-Order Fractional Mobile-Immobile Advection-Dispersion Solute Transport Model
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 6 / Issue 3 / August 2016
- Published online by Cambridge University Press:
- 20 July 2016, pp. 337-352
- Print publication:
- August 2016
-
- Article
- Export citation
A Determinant Identity Implying the Lagrange–Good Inversion Formula
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 60 / Issue 1 / February 2017
- Published online by Cambridge University Press:
- 13 June 2016, pp. 165-176
-
- Article
- Export citation
A fourth-order seven-point cubature on regular hexagons
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 19 / Issue 1 / 2016
- Published online by Cambridge University Press:
- 01 April 2016, pp. 175-185
-
- Article
-
- You have access
- Export citation
