Refine listing
Actions for selected content:
238 results in 65Cxx
Multilevel particle filters for partially observed McKean–Vlasov stochastic differential equations
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 29 January 2026, pp. 1-25
-
- Article
- Export citation
-
We consider the filtering problem associated with partially observed McKean–Vlasov stochastic differential equations (SDEs). The model consists of data that are observed at regular and discrete times; the objective is to compute the conditional expectation of (functionals) of the solutions of the SDE at the current time. This problem is challenging even in the ordinary SDE case and requires numerical approximations. Based on the ideas in Ben Rached et al. (2024) and dos Reis et al. (2023), we develop a new particle filter (PF) and multilevel particle filter (MLPF) to approximate the aforementioned expectations. We prove under assumptions that, for
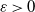 $\varepsilon>0$, to obtain a mean square error of
$\varepsilon>0$, to obtain a mean square error of 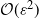 $\mathcal{O}(\varepsilon^2)$ the PF has a cost per observation time of
$\mathcal{O}(\varepsilon^2)$ the PF has a cost per observation time of 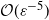 $\mathcal{O}(\varepsilon^{-5})$, and the MLPF costs
$\mathcal{O}(\varepsilon^{-5})$, and the MLPF costs 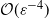 $\mathcal{O}(\varepsilon^{-4})$ (best case) or
$\mathcal{O}(\varepsilon^{-4})$ (best case) or 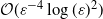 $\mathcal{O}(\varepsilon^{-4}\log(\varepsilon)^2)$ (worst case). Our theoretical results are supported by numerical experiments.
$\mathcal{O}(\varepsilon^{-4}\log(\varepsilon)^2)$ (worst case). Our theoretical results are supported by numerical experiments.
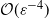
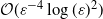
The functional discrete-time approximation of marked Hawkes risk processes
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 29 January 2026, pp. 1-42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Non-asymptotic analysis of Langevin-type Monte Carlo algorithms
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 10 December 2025, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
(Empirical) Gramian-based dimension reduction for stochastic differential equations driven by fractional Brownian motion
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 November 2025, pp. 1-32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we investigate large-scale linear systems driven by a fractional Brownian motion (fBm) with Hurst parameter
 $H\in [1/2, 1)$. We interpret these equations either in the sense of Young (
$H\in [1/2, 1)$. We interpret these equations either in the sense of Young ( $H>1/2$) or Stratonovich (
$H>1/2$) or Stratonovich ( $H=1/2$). In particular, fractional Young differential equations are well suited to modeling real-world phenomena as they capture memory effects, unlike other frameworks. Although it is very complex to solve them in high dimensions, model reduction schemes for Young or Stratonovich settings have not yet been much studied. To address this gap, we analyze important features of fundamental solutions associated with the underlying systems. We prove a weak type of semigroup property which is the foundation of studying system Gramians. From the Gramians introduced, a dominant subspace can be identified, which is shown in this paper as well. The difficulty for fractional drivers with
$H=1/2$). In particular, fractional Young differential equations are well suited to modeling real-world phenomena as they capture memory effects, unlike other frameworks. Although it is very complex to solve them in high dimensions, model reduction schemes for Young or Stratonovich settings have not yet been much studied. To address this gap, we analyze important features of fundamental solutions associated with the underlying systems. We prove a weak type of semigroup property which is the foundation of studying system Gramians. From the Gramians introduced, a dominant subspace can be identified, which is shown in this paper as well. The difficulty for fractional drivers with  $H>1/2$ is that there is no link between the corresponding Gramians and algebraic equations, making the computation very difficult. Therefore we further propose empirical Gramians that can be learned from simulation data. Subsequently, we introduce projection-based reduced-order models using the dominant subspace information. We point out that such projections are not always optimal for Stratonovich equations, as stability might not be preserved and since the error might be larger than expected. Therefore an improved reduced-order model is proposed for
$H>1/2$ is that there is no link between the corresponding Gramians and algebraic equations, making the computation very difficult. Therefore we further propose empirical Gramians that can be learned from simulation data. Subsequently, we introduce projection-based reduced-order models using the dominant subspace information. We point out that such projections are not always optimal for Stratonovich equations, as stability might not be preserved and since the error might be larger than expected. Therefore an improved reduced-order model is proposed for  $H=1/2$. We validate our techniques conducting numerical experiments on some large-scale stochastic differential equations driven by fBm resulting from spatial discretizations of fractional stochastic PDEs. Overall, our study provides useful insights into the applicability and effectiveness of reduced-order methods for stochastic systems with fractional noise, which can potentially aid in the development of more efficient computational strategies for practical applications.
$H=1/2$. We validate our techniques conducting numerical experiments on some large-scale stochastic differential equations driven by fBm resulting from spatial discretizations of fractional stochastic PDEs. Overall, our study provides useful insights into the applicability and effectiveness of reduced-order methods for stochastic systems with fractional noise, which can potentially aid in the development of more efficient computational strategies for practical applications.





On the variance reduction of Hamiltonian Monte Carlo via an approximation scheme
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 19 August 2025, pp. 1-27
-
- Article
- Export citation
-
Let
 $\pi$ be a probability distribution in
$\pi$ be a probability distribution in  $\mathbb{R}^d$ and f a test function, and consider the problem of variance reduction in estimating
$\mathbb{R}^d$ and f a test function, and consider the problem of variance reduction in estimating  $\mathbb{E}_\pi(f)$. We first construct a sequence of estimators for
$\mathbb{E}_\pi(f)$. We first construct a sequence of estimators for  $\mathbb{E}_\pi (f)$, say
$\mathbb{E}_\pi (f)$, say  $({1}/{k})\sum_{i=0}^{k-1} g_n(X_i)$, where the
$({1}/{k})\sum_{i=0}^{k-1} g_n(X_i)$, where the  $X_i$ are samples from
$X_i$ are samples from  $\pi$ generated by the Metropolized Hamiltonian Monte Carlo algorithm and
$\pi$ generated by the Metropolized Hamiltonian Monte Carlo algorithm and  $g_n$ is the approximate solution of the Poisson equation through the weak approximate scheme recently invented by Mijatović and Vogrinc (2018). Then we prove under some regularity assumptions that the estimation error variance
$g_n$ is the approximate solution of the Poisson equation through the weak approximate scheme recently invented by Mijatović and Vogrinc (2018). Then we prove under some regularity assumptions that the estimation error variance  $\sigma_\pi^2(g_n)$ can be as arbitrarily small as the approximation order parameter
$\sigma_\pi^2(g_n)$ can be as arbitrarily small as the approximation order parameter  $n\rightarrow\infty$. To illustrate, we confirm that the assumptions are satisfied by two typical concrete models, a Bayesian linear inverse problem and a two-component mixture of Gaussian distributions.
$n\rightarrow\infty$. To illustrate, we confirm that the assumptions are satisfied by two typical concrete models, a Bayesian linear inverse problem and a two-component mixture of Gaussian distributions.










How to beat a Bayesian adversary
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 37 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 28 March 2025, pp. 73-95
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Perturbation theory for killed Markov processes and quasi-stationary distributions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 19 March 2025, pp. 1138-1165
- Print publication:
- September 2025
-
- Article
- Export citation
-
Motivated by recent developments of quasi-stationary Monte Carlo methods, we investigate the stability of quasi-stationary distributions of killed Markov processes under perturbations of the generator. We first consider a general bounded self-adjoint perturbation operator, and then study a particular unbounded perturbation corresponding to truncation of the killing rate. In both scenarios, we quantify the difference between eigenfunctions of the smallest eigenvalue of the perturbed and unperturbed generators in a Hilbert space norm. As a consequence,
 $\mathcal{L}^1$-norm estimates of the difference of the resulting quasi-stationary distributions in terms of the perturbation are provided.
$\mathcal{L}^1$-norm estimates of the difference of the resulting quasi-stationary distributions in terms of the perturbation are provided.

MICRO-MACRO PARAREAL, FROM ORDINARY DIFFERENTIAL EQUATIONS TO STOCHASTIC DIFFERENTIAL EQUATIONS AND BACK AGAIN
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 67 / 2025
- Published online by Cambridge University Press:
- 17 March 2025, e13
-
- Article
- Export citation
Optimal convergence rates of MCMC integration for functions with unbounded second moment
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 14 February 2025, pp. 1069-1075
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the Markov chain Monte Carlo estimator for numerical integration for functions that do not need to be square integrable with respect to the invariant distribution. For chains with a spectral gap we show that the absolute mean error for
 $L^p$ functions, with
$L^p$ functions, with  $p \in (1,2)$, decreases like
$p \in (1,2)$, decreases like  $n^{({1}/{p}) -1}$, which is known to be the optimal rate. This improves currently known results where an additional parameter
$n^{({1}/{p}) -1}$, which is known to be the optimal rate. This improves currently known results where an additional parameter  $\delta \gt 0$ appears and the convergence is of order
$\delta \gt 0$ appears and the convergence is of order  $n^{(({1+\delta})/{p})-1}$.
$n^{(({1+\delta})/{p})-1}$.





Convergence speed and approximation accuracy of numerical MCMC
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 02 December 2024, pp. 101-133
- Print publication:
- March 2025
-
- Article
- Export citation
-
When implementing Markov Chain Monte Carlo (MCMC) algorithms, perturbation caused by numerical errors is sometimes inevitable. This paper studies how the perturbation of MCMC affects the convergence speed and approximation accuracy. Our results show that when the original Markov chain converges to stationarity fast enough and the perturbed transition kernel is a good approximation to the original transition kernel, the corresponding perturbed sampler has fast convergence speed and high approximation accuracy as well. Our convergence analysis is conducted under either the Wasserstein metric or the
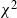 $\chi^2$ metric, both are widely used in the literature. The results can be extended to obtain non-asymptotic error bounds for MCMC estimators. We demonstrate how to apply our convergence and approximation results to the analysis of specific sampling algorithms, including Random walk Metropolis, Metropolis adjusted Langevin algorithm with perturbed target densities, and parallel tempering Monte Carlo with perturbed densities. Finally, we present some simple numerical examples to verify our theoretical claims.
$\chi^2$ metric, both are widely used in the literature. The results can be extended to obtain non-asymptotic error bounds for MCMC estimators. We demonstrate how to apply our convergence and approximation results to the analysis of specific sampling algorithms, including Random walk Metropolis, Metropolis adjusted Langevin algorithm with perturbed target densities, and parallel tempering Monte Carlo with perturbed densities. Finally, we present some simple numerical examples to verify our theoretical claims.
Early warning signs for SPDEs with continuous spectrum
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 36 / Issue 4 / August 2025
- Published online by Cambridge University Press:
- 04 October 2024, pp. 665-704
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Finite element approximations for stochastic control problems with unbounded state space
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 October 2024, pp. 367-394
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stochastic gradient descent for barycenters in Wasserstein space
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 September 2024, pp. 15-43
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the speed of convergence of discrete Pickands constants to continuous ones
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 31 July 2024, pp. 111-135
- Print publication:
- March 2025
-
- Article
- Export citation
-
In this manuscript, we address open questions raised by Dieker and Yakir (2014), who proposed a novel method of estimating (discrete) Pickands constants
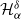 $\mathcal{H}^\delta_\alpha$ using a family of estimators
$\mathcal{H}^\delta_\alpha$ using a family of estimators 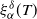 $\xi^\delta_\alpha(T)$,
$\xi^\delta_\alpha(T)$, 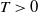 $T>0$, where
$T>0$, where 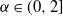 $\alpha\in(0,2]$ is the Hurst parameter, and
$\alpha\in(0,2]$ is the Hurst parameter, and 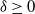 $\delta\geq0$ is the step size of the regular discretization grid. We derive an upper bound for the discretization error
$\delta\geq0$ is the step size of the regular discretization grid. We derive an upper bound for the discretization error 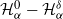 $\mathcal{H}_\alpha^0 - \mathcal{H}_\alpha^\delta$, whose rate of convergence agrees with Conjecture 1 of Dieker and Yakir (2014) in the case
$\mathcal{H}_\alpha^0 - \mathcal{H}_\alpha^\delta$, whose rate of convergence agrees with Conjecture 1 of Dieker and Yakir (2014) in the case 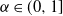 $\alpha\in(0,1]$ and agrees up to logarithmic terms for
$\alpha\in(0,1]$ and agrees up to logarithmic terms for 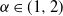 $\alpha\in(1,2)$. Moreover, we show that all moments of
$\alpha\in(1,2)$. Moreover, we show that all moments of 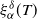 $\xi_\alpha^\delta(T)$ are uniformly bounded and the bias of the estimator decays no slower than
$\xi_\alpha^\delta(T)$ are uniformly bounded and the bias of the estimator decays no slower than 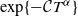 $\exp\{-\mathcal CT^{\alpha}\}$, as T becomes large.
$\exp\{-\mathcal CT^{\alpha}\}$, as T becomes large.
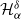
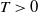
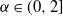
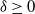
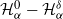
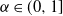
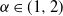
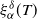
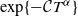
Error bounds for one-dimensional constrained Langevin approximations for nearly density-dependent Markov chains
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 26 July 2024, pp. 825-867
- Print publication:
- September 2024
-
- Article
- Export citation
Convergence of hybrid slice sampling via spectral gap
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 25 July 2024, pp. 1440-1466
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A remark on exact simulation of tempered stable Ornstein–Uhlenbeck processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 02 May 2024, pp. 1196-1198
- Print publication:
- December 2024
-
- Article
-
- You have access
- HTML
- Export citation
Antithetic multilevel particle filters
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 16 April 2024, pp. 1400-1439
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we consider the filtering of partially observed multidimensional diffusion processes that are observed regularly at discrete times. This is a challenging problem which requires the use of advanced numerical schemes based upon time-discretization of the diffusion process and then the application of particle filters. Perhaps the state-of-the-art method for moderate-dimensional problems is the multilevel particle filter of Jasra et al. (SIAM J. Numer. Anal. 55 (2017), 3068–3096). This is a method that combines multilevel Monte Carlo and particle filters. The approach in that article is based intrinsically upon an Euler discretization method. We develop a new particle filter based upon the antithetic truncated Milstein scheme of Giles and Szpruch (Ann. Appl. Prob. 24 (2014), 1585–1620). We show empirically for a class of diffusion problems that, for
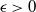 $\epsilon>0$ given, the cost to produce a mean squared error (MSE) of
$\epsilon>0$ given, the cost to produce a mean squared error (MSE) of 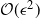 $\mathcal{O}(\epsilon^2)$ in the estimation of the filter is
$\mathcal{O}(\epsilon^2)$ in the estimation of the filter is 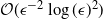 $\mathcal{O}(\epsilon^{-2}\log(\epsilon)^2)$. In the case of multidimensional diffusions with non-constant diffusion coefficient, the method of Jasra et al. (2017) requires a cost of
$\mathcal{O}(\epsilon^{-2}\log(\epsilon)^2)$. In the case of multidimensional diffusions with non-constant diffusion coefficient, the method of Jasra et al. (2017) requires a cost of 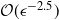 $\mathcal{O}(\epsilon^{-2.5})$ to achieve the same MSE.
$\mathcal{O}(\epsilon^{-2.5})$ to achieve the same MSE.
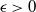
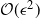
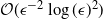
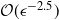
PDMP Monte Carlo methods for piecewise smooth densities
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 12 March 2024, pp. 1153-1194
- Print publication:
- December 2024
-
- Article
- Export citation
Game-theoretic policy computing and simulation for blockchained buffering system via diffusion approximation
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 3 / July 2024
- Published online by Cambridge University Press:
- 12 January 2024, pp. 503-538
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
