Refine listing
Actions for selected content:
532 results in 60Exx
Compound Poisson limit theorems for Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 1 / March 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 24-34
- Print publication:
- March 1997
-
- Article
- Export citation
Variants of the Choquet–Deny theorem with applications
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 1 / March 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 101-106
- Print publication:
- March 1997
-
- Article
- Export citation
Some majorization orderings of heterogeneity in a class of epidemics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 1 / March 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 84-93
- Print publication:
- March 1997
-
- Article
- Export citation
Shapes of Rectangular Prisms After Repeated Random Division
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 29 / Issue 1 / March 1997
- Published online by Cambridge University Press:
- 01 July 2016, pp. 26-37
- Print publication:
- March 1997
-
- Article
- Export citation
Properties of moments for s-order equilibrium distributions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 4 / December 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1108-1111
- Print publication:
- December 1996
-
- Article
- Export citation
On identifiability and order of continuous-time aggregated Markov chains, Markov-modulated Poisson processes, and phase-type distributions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 640-653
- Print publication:
- September 1996
-
- Article
- Export citation
Stein's method for geometric approximation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 707-713
- Print publication:
- September 1996
-
- Article
- Export citation
Comparing sums of exchangeable Bernoulli random variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 2 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 285-310
- Print publication:
- September 1996
-
- Article
- Export citation
On closure of some partial orderings under mixtures
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 698-706
- Print publication:
- September 1996
-
- Article
- Export citation
Randomized multihit models and their identification
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 2 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 458-471
- Print publication:
- September 1996
-
- Article
- Export citation
A note on disjoint-occurrence inequalities for marked Poisson point processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 2 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 420-426
- Print publication:
- September 1996
-
- Article
- Export citation
Multivariate Bonferroni-type lower bounds
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 729-740
- Print publication:
- September 1996
-
- Article
- Export citation
Perpetuities with thin tails
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 28 / Issue 2 / June 1996
- Published online by Cambridge University Press:
- 01 July 2016, pp. 463-480
- Print publication:
- June 1996
-
- Article
- Export citation
-
We investigate the behaviour of P(R ≧ r) and P(R ≦ −r) as r → ∞for the random variable
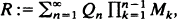 where
where 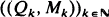 is an independent, identically distributed sequence with P(− 1 ≦ M ≦ 1) = 1. Random variables of this type appear in insurance mathematics, as solutions of stochastic difference equations, in the analysis of probabilistic algorithms and elsewhere. Exponential and Poissonian tail behaviour can arise.
is an independent, identically distributed sequence with P(− 1 ≦ M ≦ 1) = 1. Random variables of this type appear in insurance mathematics, as solutions of stochastic difference equations, in the analysis of probabilistic algorithms and elsewhere. Exponential and Poissonian tail behaviour can arise.
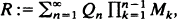 where
where 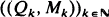 is an independent, identically distributed sequence with P(− 1 ≦ M ≦ 1) = 1. Random variables of this type appear in insurance mathematics, as solutions of stochastic difference equations, in the analysis of probabilistic algorithms and elsewhere. Exponential and Poissonian tail behaviour can arise.
is an independent, identically distributed sequence with P(− 1 ≦ M ≦ 1) = 1. Random variables of this type appear in insurance mathematics, as solutions of stochastic difference equations, in the analysis of probabilistic algorithms and elsewhere. Exponential and Poissonian tail behaviour can arise.Poisson and compound Poisson approximations for random sums of random variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 1 / March 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 127-137
- Print publication:
- March 1996
-
- Article
- Export citation
An operational calculus for probability distributions via Laplace transforms
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 28 / Issue 1 / March 1996
- Published online by Cambridge University Press:
- 01 July 2016, pp. 75-113
- Print publication:
- March 1996
-
- Article
- Export citation
Bonferroni inequalities and deviations of discrete distributions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 1 / March 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 115-121
- Print publication:
- March 1996
-
- Article
- Export citation
Distributions and expectations of singular random variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 32 / Issue 4 / December 1995
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1032-1040
- Print publication:
- December 1995
-
- Article
- Export citation
Characterization of a general class of life-testing models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 32 / Issue 2 / June 1995
- Published online by Cambridge University Press:
- 14 July 2016, pp. 548-553
- Print publication:
- June 1995
-
- Article
- Export citation
Limit laws for a stochastic process and random recursion arising in probabilistic modelling
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 27 / Issue 1 / March 1995
- Published online by Cambridge University Press:
- 01 July 2016, pp. 185-202
- Print publication:
- March 1995
-
- Article
- Export citation
Max-infinite divisibility and multivariate total positivity
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 31 / Issue 3 / September 1994
- Published online by Cambridge University Press:
- 14 July 2016, pp. 721-730
- Print publication:
- September 1994
-
- Article
- Export citation
