Refine listing
Actions for selected content:
108 results in 62Hxx
On stochastic properties of random age and remaining lifetime for populations of manufactured items
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 23 April 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the study of bivariate and conditional dynamic negative cumulative extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SPATIAL STATISTICAL INFERENCE FROM A DECISION-THEORETIC VIEWPOINT WITH APPLICATION TO NON-GAUSSIAN ENVIRONMENTAL DATA
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 113 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 10 December 2025, pp. 375-376
- Print publication:
- April 2026
-
- Article
-
- You have access
- HTML
- Export citation
Negative dependence in knockout tournaments
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 04 December 2025, pp. 536-551
- Print publication:
- June 2026
-
- Article
-
- You have access
- HTML
- Export citation
-
Negative dependence in tournaments has received attention in the literature. The property of negative orthant dependence (NOD) was proved for different tournament models with a special proof for each model. For general round-robin tournaments and knockout tournaments with random draws, Malinovsky and Rinott (2023) unified and simplified many existing results in the literature by proving a stronger property, negative association (NA). For a knockout tournament with a non-random draw, they presented an example to illustrate that
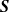 ${\boldsymbol{S}}$ is NOD but not NA. However, their proof is not correct. In this paper, we establish the properties of negative regression dependence (NRD), negative left-tail dependence (NLTD), and negative right-tail dependence (NRTD) for a knockout tournament with a random draw and with players being of equal strength. For a knockout tournament with a non-random draw and with equal strength, we prove that
${\boldsymbol{S}}$ is NOD but not NA. However, their proof is not correct. In this paper, we establish the properties of negative regression dependence (NRD), negative left-tail dependence (NLTD), and negative right-tail dependence (NRTD) for a knockout tournament with a random draw and with players being of equal strength. For a knockout tournament with a non-random draw and with equal strength, we prove that 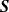 ${\boldsymbol{S}}$ is NA and NRTD, while
${\boldsymbol{S}}$ is NA and NRTD, while 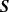 ${\boldsymbol{S}}$ is, in general, not NRD or NLTD.
${\boldsymbol{S}}$ is, in general, not NRD or NLTD.
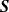
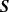
Infinitely resizable urn models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 24 November 2025, pp. 501-535
- Print publication:
- June 2026
-
- Article
- Export citation
VARIABLE SELECTION IN MULTIVARIATE DATA BY ANALYSIS OF DATA PATTERN
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 112 / Issue 3 / December 2025
- Published online by Cambridge University Press:
- 11 August 2025, pp. 572-573
- Print publication:
- December 2025
-
- Article
-
- You have access
- HTML
- Export citation
Estranged facets and k-facets of Gaussian random point sets
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 02 April 2025, pp. 859-875
- Print publication:
- September 2025
-
- Article
- Export citation
-
Gaussian random polytopes have received a lot of attention, especially in the case where the dimension is fixed and the number of points goes to infinity. Our focus is on the less-studied case where the dimension goes to infinity and the number of points is proportional to the dimension d. We study several natural quantities associated with Gaussian random polytopes in this setting. First, we show that the expected number of facets is equal to
 $C(\alpha)^{d+o(d)}$, where
$C(\alpha)^{d+o(d)}$, where  $C(\alpha)$ is some constant which depends on the constant of proportionality
$C(\alpha)$ is some constant which depends on the constant of proportionality  $\alpha$. We also extend this result to the expected number of k-facets. We then consider the more difficult problem of the asymptotics of the expected number of pairs of estranged facets of a Gaussian random polytope. When the number of points is 2d, we determine the constant C such that the expected number of pairs of estranged facets is equal to
$\alpha$. We also extend this result to the expected number of k-facets. We then consider the more difficult problem of the asymptotics of the expected number of pairs of estranged facets of a Gaussian random polytope. When the number of points is 2d, we determine the constant C such that the expected number of pairs of estranged facets is equal to  $C^{d+o(d)}$.
$C^{d+o(d)}$.




EXPLORING OUT-OF-SAMPLE PREDICTION AND SPATIAL DEPENDENCY FOR COMPLEX BIG DATA
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 111 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 10 February 2025, pp. 380-382
- Print publication:
- April 2025
-
- Article
-
- You have access
- HTML
- Export citation
On a class of bivariate distributions built of q-ultraspherical polynomials
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics , First View
- Published online by Cambridge University Press:
- 02 December 2024, pp. 1-34
-
- Article
- Export citation
An MBO method for modularity optimisation based on total variation and signless total variation
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 37 / Issue 3 / June 2026
- Published online by Cambridge University Press:
- 25 November 2024, pp. 743-825
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Almost exact recovery in noisy semi-supervised learning
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 November 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The dutch draw: constructing a universal baseline for binary classification problems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 19 September 2024, pp. 475-493
- Print publication:
- June 2025
-
- Article
- Export citation
-
Novel prediction methods should always be compared to a baseline to determine their performance. Without this frame of reference, the performance score of a model is basically meaningless. What does it mean when a model achieves an
 $F_1$ of 0.8 on a test set? A proper baseline is, therefore, required to evaluate the ‘goodness’ of a performance score. Comparing results with the latest state-of-the-art model is usually insightful. However, being state-of-the-art is dynamic, as newer models are continuously developed. Contrary to an advanced model, it is also possible to use a simple dummy classifier. However, the latter model could be beaten too easily, making the comparison less valuable. Furthermore, most existing baselines are stochastic and need to be computed repeatedly to get a reliable expected performance, which could be computationally expensive. We present a universal baseline method for all binary classification models, named the Dutch Draw (DD). This approach weighs simple classifiers and determines the best classifier to use as a baseline. Theoretically, we derive the DD baseline for many commonly used evaluation measures and show that in most situations it reduces to (almost) always predicting either zero or one. Summarizing, the DD baseline is general, as it is applicable to any binary classification problem; simple, as it can be quickly determined without training or parameter tuning; and informative, as insightful conclusions can be drawn from the results. The DD baseline serves two purposes. First, it is a robust and universal baseline that enables comparisons across research papers. Second, it provides a sanity check during the prediction model’s development process. When a model does not outperform the DD baseline, it is a major warning sign.
$F_1$ of 0.8 on a test set? A proper baseline is, therefore, required to evaluate the ‘goodness’ of a performance score. Comparing results with the latest state-of-the-art model is usually insightful. However, being state-of-the-art is dynamic, as newer models are continuously developed. Contrary to an advanced model, it is also possible to use a simple dummy classifier. However, the latter model could be beaten too easily, making the comparison less valuable. Furthermore, most existing baselines are stochastic and need to be computed repeatedly to get a reliable expected performance, which could be computationally expensive. We present a universal baseline method for all binary classification models, named the Dutch Draw (DD). This approach weighs simple classifiers and determines the best classifier to use as a baseline. Theoretically, we derive the DD baseline for many commonly used evaluation measures and show that in most situations it reduces to (almost) always predicting either zero or one. Summarizing, the DD baseline is general, as it is applicable to any binary classification problem; simple, as it can be quickly determined without training or parameter tuning; and informative, as insightful conclusions can be drawn from the results. The DD baseline serves two purposes. First, it is a robust and universal baseline that enables comparisons across research papers. Second, it provides a sanity check during the prediction model’s development process. When a model does not outperform the DD baseline, it is a major warning sign.

Exact recovery of community detection in k-community Gaussian mixture models
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 36 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 18 September 2024, pp. 491-523
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the community detection problem on a Gaussian mixture model, in which vertices are divided into
 $k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
$k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.

The limiting spectral distribution of large random permutation matrices
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 12 April 2024, pp. 1301-1318
- Print publication:
- December 2024
-
- Article
- Export citation
-
We explore the limiting spectral distribution of large-dimensional random permutation matrices, assuming the underlying population distribution possesses a general dependence structure. Let
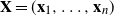 $\textbf X = (\textbf x_1,\ldots,\textbf x_n)$
$\textbf X = (\textbf x_1,\ldots,\textbf x_n)$ 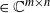 $\in \mathbb{C} ^{m \times n}$ be an
$\in \mathbb{C} ^{m \times n}$ be an 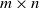 $m \times n$ data matrix after self-normalization (n samples and m features), where
$m \times n$ data matrix after self-normalization (n samples and m features), where 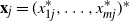 $\textbf x_j = (x_{1j}^{*},\ldots, x_{mj}^{*} )^{*}$. Specifically, we generate a permutation matrix
$\textbf x_j = (x_{1j}^{*},\ldots, x_{mj}^{*} )^{*}$. Specifically, we generate a permutation matrix 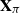 $\textbf X_\pi$ by permuting the entries of
$\textbf X_\pi$ by permuting the entries of 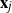 $\textbf x_j$
$\textbf x_j$ 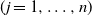 $(j=1,\ldots,n)$ and demonstrate that the empirical spectral distribution of
$(j=1,\ldots,n)$ and demonstrate that the empirical spectral distribution of 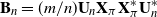 $\textbf {B}_n = ({m}/{n})\textbf{U} _{n} \textbf{X} _\pi \textbf{X} _\pi^{*} \textbf{U} _{n}^{*}$ weakly converges to the generalized Marčenko–Pastur distribution with probability 1, where
$\textbf {B}_n = ({m}/{n})\textbf{U} _{n} \textbf{X} _\pi \textbf{X} _\pi^{*} \textbf{U} _{n}^{*}$ weakly converges to the generalized Marčenko–Pastur distribution with probability 1, where 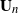 $\textbf{U} _n$ is a sequence of
$\textbf{U} _n$ is a sequence of 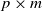 $p \times m$ non-random complex matrices. The conditions we require are
$p \times m$ non-random complex matrices. The conditions we require are 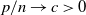 $p/n \to c >0$ and
$p/n \to c >0$ and 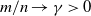 $m/n \to \gamma > 0$.
$m/n \to \gamma > 0$.
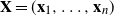
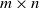
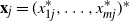
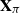
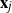
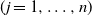
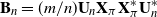
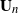
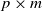
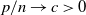
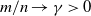
The unified extropy and its versions in classical and Dempster–Shafer theories
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 23 October 2023, pp. 685-696
- Print publication:
- June 2024
-
- Article
- Export citation
ON THE N-POINT CORRELATION OF VAN DER CORPUT SEQUENCES
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 109 / Issue 3 / June 2024
- Published online by Cambridge University Press:
- 15 September 2023, pp. 471-475
- Print publication:
- June 2024
-
- Article
- Export citation
-
We derive an explicit formula for the N-point correlation
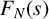 $F_N(s)$ of the van der Corput sequence in base
$F_N(s)$ of the van der Corput sequence in base 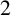 $2$ for all
$2$ for all 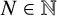 $N \in \mathbb {N}$ and
$N \in \mathbb {N}$ and 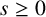 $s \geq 0$. The formula can be evaluated without explicit knowledge about the elements of the van der Corput sequence. This constitutes the first example of an exact closed-form expression of
$s \geq 0$. The formula can be evaluated without explicit knowledge about the elements of the van der Corput sequence. This constitutes the first example of an exact closed-form expression of 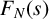 $F_N(s)$ for all
$F_N(s)$ for all 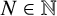 $N \in \mathbb {N}$ and all
$N \in \mathbb {N}$ and all 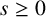 $s \geq 0$ which does not require explicit knowledge about the involved sequence. Moreover, it can be immediately read off that
$s \geq 0$ which does not require explicit knowledge about the involved sequence. Moreover, it can be immediately read off that 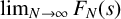 $\lim _{N \to \infty } F_N(s)$ exists only for
$\lim _{N \to \infty } F_N(s)$ exists only for 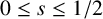 $0 \leq s \leq 1/2$.
$0 \leq s \leq 1/2$.
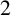
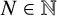
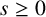
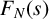
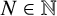
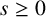
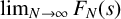
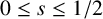
Exchangeable FGM copulas
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 24 August 2023, pp. 205-234
- Print publication:
- March 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
EXTRACTING FEATURES FROM EIGENFUNCTIONS: HIGHER CHEEGER CONSTANTS AND SPARSE EIGENBASIS APPROXIMATION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 108 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 22 August 2023, pp. 511-512
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
Asymptotic expansion of the expected Minkowski functional for isotropic central limit random fields
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 14 July 2023, pp. 1390-1414
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
Asymptotic results on tail moment and tail central moment for dependent risks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 08 May 2023, pp. 1116-1143
- Print publication:
- December 2023
-
- Article
- Export citation
