Refine listing
Actions for selected content:
532 results in 60Exx
On Exact Sampling of Nonnegative Infinitely Divisible Random Variables
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 3 / September 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 842-873
- Print publication:
- September 2012
-
- Article
-
- You have access
- Export citation
Spatial Stit Tessellations: Distributional Results for I-Segments
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 3 / September 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 635-654
- Print publication:
- September 2012
-
- Article
-
- You have access
- Export citation
L1-SMOOTHING FOR THE ORNSTEIN–UHLENBECK SEMIGROUP
- Part of
-
- Journal:
- Mathematika / Volume 59 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 02 August 2012, pp. 160-168
- Print publication:
- January 2013
-
- Article
- Export citation
A Note on the Failure Rates in Finite Mixed Populations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 405-415
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
On Tail Bounds for Random Recursive Trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 566-581
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
On a Class of Distributions Stable Under Random Summation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 303-318
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
On the Residual and Inactivity Times of the Components of Used Coherent Systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 385-404
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
Advances in Complete Mixability
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 430-440
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
On the Joint Behavior of Types of Coupons in Generalized Coupon Collection
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 429-451
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
Increasing Hazard Rate of Mixtures for Natural Exponential Families
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 373-390
- Print publication:
- June 2012
-
- Article
-
- You have access
- Export citation
Pareto Lévy Measures and Multivariate Regular Variation
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 44 / Issue 1 / March 2012
- Published online by Cambridge University Press:
- 04 January 2016, pp. 117-138
- Print publication:
- March 2012
-
- Article
-
- You have access
- Export citation
-
We consider regular variation of a Lévy process X := (X t)t≥0 in
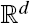 with Lévy measure Π, emphasizing the dependence between jumps of its components. By transforming the one-dimensional marginal Lévy measures to those of a standard 1-stable Lévy process, we decouple the marginal Lévy measures from the dependence structure. The dependence between the jumps is modeled by a so-called Pareto Lévy measure, which is a natural standardization in the context of regular variation. We characterize multivariate regularly variation of X by its one-dimensional marginal Lévy measures and the Pareto Lévy measure. Moreover, we define upper and lower tail dependence coefficients for the Lévy measure, which also apply to the multivariate distributions of the process. Finally, we present graphical tools to visualize the dependence structure in terms of the spectral density and the tail integral for homogeneous and nonhomogeneous Pareto Lévy measures.
with Lévy measure Π, emphasizing the dependence between jumps of its components. By transforming the one-dimensional marginal Lévy measures to those of a standard 1-stable Lévy process, we decouple the marginal Lévy measures from the dependence structure. The dependence between the jumps is modeled by a so-called Pareto Lévy measure, which is a natural standardization in the context of regular variation. We characterize multivariate regularly variation of X by its one-dimensional marginal Lévy measures and the Pareto Lévy measure. Moreover, we define upper and lower tail dependence coefficients for the Lévy measure, which also apply to the multivariate distributions of the process. Finally, we present graphical tools to visualize the dependence structure in terms of the spectral density and the tail integral for homogeneous and nonhomogeneous Pareto Lévy measures.
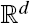 with Lévy measure Π, emphasizing the dependence between jumps of its components. By transforming the one-dimensional marginal Lévy measures to those of a standard 1-stable Lévy process, we decouple the marginal Lévy measures from the dependence structure. The dependence between the jumps is modeled by a so-called Pareto Lévy measure, which is a natural standardization in the context of regular variation. We characterize multivariate regularly variation of
with Lévy measure Π, emphasizing the dependence between jumps of its components. By transforming the one-dimensional marginal Lévy measures to those of a standard 1-stable Lévy process, we decouple the marginal Lévy measures from the dependence structure. The dependence between the jumps is modeled by a so-called Pareto Lévy measure, which is a natural standardization in the context of regular variation. We characterize multivariate regularly variation of Continuous, Discrete, and Conditional Scan Statistics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 1 / March 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 199-209
- Print publication:
- March 2012
-
- Article
-
- You have access
- Export citation
A Fourier Approach for the Level Crossings of Shot Noise Processes with Jumps
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 1 / March 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 100-113
- Print publication:
- March 2012
-
- Article
-
- You have access
- Export citation
Distribution of Clump Statistics for a Collection of Words
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 4 / December 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1049-1059
- Print publication:
- December 2011
-
- Article
-
- You have access
- Export citation
Some Inequalities of Linear Combinations of Independent Random Variables. I.
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 4 / December 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1179-1188
- Print publication:
- December 2011
-
- Article
-
- You have access
- Export citation
Convergence Properties in Certain Occupancy Problems Including the Karlin-Rouault Law
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 4 / December 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1095-1113
- Print publication:
- December 2011
-
- Article
-
- You have access
- Export citation
Exchangeability-type properties of asset prices
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 3 / September 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 666-687
- Print publication:
- September 2011
-
- Article
-
- You have access
- Export citation
Signature-Based Representations for the Reliability of Systems with Heterogeneous Components
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 3 / September 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 856-867
- Print publication:
- September 2011
-
- Article
-
- You have access
- Export citation
On the Convolution of Heterogeneous Bernoulli Random Variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 3 / September 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 877-884
- Print publication:
- September 2011
-
- Article
-
- You have access
- Export citation
Characterization of tails through hazard rate and convolution closure properties
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue A / August 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 123-132
- Print publication:
- August 2011
-
- Article
-
- You have access
- Export citation
