Refine listing
Actions for selected content:
1446 results in 60Kxx
How fast can the chord length distribution decay?
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 504-523
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Contact Process with Destruction of Cubes and Hyperplanes: Forest Fires Versus Tornadoes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 352-365
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Exact Monte Carlo simulation for fork-join networks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 484-503
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Phenotypic diversity and population growth in a fluctuating environment
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 375-398
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
-
Organisms adapt to fluctuating environments by regulating their dynamics, and by adjusting their phenotypes to environmental changes. We model population growth using multitype branching processes in random environments, where the offspring distribution of some organism having trait t ∈
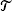 in environment e ∈ ε is given by some (fixed) distribution ϒ t,e on ℕ. Then, the phenotypes are attributed using a distribution (strategy) πt,e on the trait space . We look for the optimal strategy πt,e , t ∈ , e ∈ ε, maximizing the net growth rate or Lyapounov exponent, and characterize the set of optimal strategies. This is considered for various models of interest in biology: hereditary versus nonhereditary strategies and strategies involving or not involving a sensing mechanism. Our main results are obtained in the setting of nonhereditary strategies: thanks to a reduction to simple branching processes in a random environment, we derive an exact expression for the net growth rate and a characterization of optimal strategies. We also focus on typical genealogies, that is, we consider the problem of finding the typical lineage of a randomly chosen organism.
in environment e ∈ ε is given by some (fixed) distribution ϒ t,e on ℕ. Then, the phenotypes are attributed using a distribution (strategy) πt,e on the trait space . We look for the optimal strategy πt,e , t ∈ , e ∈ ε, maximizing the net growth rate or Lyapounov exponent, and characterize the set of optimal strategies. This is considered for various models of interest in biology: hereditary versus nonhereditary strategies and strategies involving or not involving a sensing mechanism. Our main results are obtained in the setting of nonhereditary strategies: thanks to a reduction to simple branching processes in a random environment, we derive an exact expression for the net growth rate and a characterization of optimal strategies. We also focus on typical genealogies, that is, we consider the problem of finding the typical lineage of a randomly chosen organism.
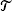 in environment
in environment Bounding basic characteristics of spatial epidemics with a new percolation model
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 335-347
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Managing Queues with Heterogeneous Servers
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 435-452
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Quasistationary Distributions and Fleming-Viot Processes in Finite Spaces
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 322-332
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Hitting Times and the Running Maximum of Markovian Growth-Collapse Processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 295-312
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Concave Renewal Functions do not Imply DFR Interrenewal Times
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 583-588
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
On the Markov Transition Kernels for First Passage Percolation on the Ladder
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 366-388
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
A Stochastic Breakdown Model for an Unreliable Web Server System and an Optimal Admission Control Policy
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 453-466
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
Simulation-Based Computation of the Workload Correlation Function in a Lévy-Driven Queue
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 114-130
- Print publication:
- March 2011
-
- Article
-
- You have access
- Export citation
On New Classes of Extreme Shock Models and Some Generalizations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 258-270
- Print publication:
- March 2011
-
- Article
-
- You have access
- Export citation
Asymptotic Fluid Optimality and Efficiency of the Tracking Policy for Bandwidth-Sharing Networks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 90-113
- Print publication:
- March 2011
-
- Article
-
- You have access
- Export citation
Large Deviations for the Graph Distance in Supercritical Continuum Percolation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 154-172
- Print publication:
- March 2011
-
- Article
-
- You have access
- Export citation
Utility Optimization in Congested Queueing Networks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 68-89
- Print publication:
- March 2011
-
- Article
-
- You have access
- Export citation
Matchmaking and Testing for Exponentiality in the M/G/∞ Queue
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 131-144
- Print publication:
- March 2011
-
- Article
-
- You have access
- Export citation
A Simple Model for Random Oscillations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 47 / Issue 4 / December 2010
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1164-1173
- Print publication:
- December 2010
-
- Article
-
- You have access
- Export citation
Information ranking and power laws on trees
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 42 / Issue 4 / December 2010
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1057-1093
- Print publication:
- December 2010
-
- Article
-
- You have access
- Export citation
-
In this paper we consider the stochastic analysis of information ranking algorithms of large interconnected data sets, e.g. Google's PageRank algorithm for ranking pages on the World Wide Web. The stochastic formulation of the problem results in an equation of the form
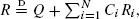 where N, Q, {R i }i≥1, and {C, C i }i≥1 are independent nonnegative random variables, the {C, C i }i≥1 are identically distributed, and the {R i }i≥1 are independent copies of
where N, Q, {R i }i≥1, and {C, C i }i≥1 are independent nonnegative random variables, the {C, C i }i≥1 are identically distributed, and the {R i }i≥1 are independent copies of 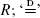 stands for equality in distribution. We study the asymptotic properties of the distribution of R that, in the context of PageRank, represents the frequencies of highly ranked pages. The preceding equation is interesting in its own right since it belongs to a more general class of weighted branching processes that have been found to be useful in the analysis of many other algorithms. Our first main result shows that if ENE[C α] = 1, α > 0, and Q, N satisfy additional moment conditions, then R has a power law distribution of index α. This result is obtained using a new approach based on an extension of Goldie's (1991) implicit renewal theorem. Furthermore, when N is regularly varying of index α > 1, ENE[C α] < 1, and Q, C have higher moments than α, then the distributions of R and N are tail equivalent. The latter result is derived via a novel sample path large deviation method for recursive random sums. Similarly, we characterize the situation when the distribution of R is determined by the tail of Q. The preceding approaches may be of independent interest, as they can be used for analyzing other functionals on trees. We also briefly discuss the engineering implications of our results.
stands for equality in distribution. We study the asymptotic properties of the distribution of R that, in the context of PageRank, represents the frequencies of highly ranked pages. The preceding equation is interesting in its own right since it belongs to a more general class of weighted branching processes that have been found to be useful in the analysis of many other algorithms. Our first main result shows that if ENE[C α] = 1, α > 0, and Q, N satisfy additional moment conditions, then R has a power law distribution of index α. This result is obtained using a new approach based on an extension of Goldie's (1991) implicit renewal theorem. Furthermore, when N is regularly varying of index α > 1, ENE[C α] < 1, and Q, C have higher moments than α, then the distributions of R and N are tail equivalent. The latter result is derived via a novel sample path large deviation method for recursive random sums. Similarly, we characterize the situation when the distribution of R is determined by the tail of Q. The preceding approaches may be of independent interest, as they can be used for analyzing other functionals on trees. We also briefly discuss the engineering implications of our results.
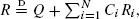 where
where 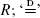 stands for equality in distribution. We study the asymptotic properties of the distribution of
stands for equality in distribution. We study the asymptotic properties of the distribution of First Passage of a Markov Additive Process and Generalized Jordan Chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 47 / Issue 4 / December 2010
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1048-1057
- Print publication:
- December 2010
-
- Article
-
- You have access
- Export citation
