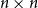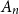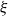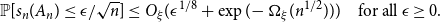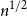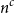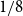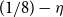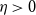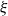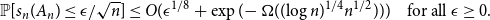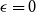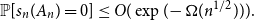Refine listing
Actions for selected content:
182 results in 60Bxx
The Asymptotic Statistics of Random Covering Surfaces
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 11 / 2023
- Published online by Cambridge University Press:
- 15 May 2023, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
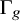 $\Gamma _{g}$ be the fundamental group of a closed connected orientable surface of genus
$\Gamma _{g}$ be the fundamental group of a closed connected orientable surface of genus 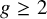 $g\geq 2$. We develop a new method for integrating over the representation space
$g\geq 2$. We develop a new method for integrating over the representation space 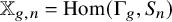 $\mathbb {X}_{g,n}=\mathrm {Hom}(\Gamma _{g},S_{n})$, where
$\mathbb {X}_{g,n}=\mathrm {Hom}(\Gamma _{g},S_{n})$, where 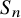 $S_{n}$ is the symmetric group of permutations of
$S_{n}$ is the symmetric group of permutations of  $\{1,\ldots ,n\}$. Equivalently, this is the space of all vertex-labeled, n-sheeted covering spaces of the closed surface of genus g.
$\{1,\ldots ,n\}$. Equivalently, this is the space of all vertex-labeled, n-sheeted covering spaces of the closed surface of genus g.Given
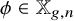 $\phi \in \mathbb {X}_{g,n}$ and
$\phi \in \mathbb {X}_{g,n}$ and 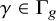 $\gamma \in \Gamma _{g}$, we let
$\gamma \in \Gamma _{g}$, we let 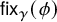 $\mathsf {fix}_{\gamma }(\phi )$ be the number of fixed points of the permutation
$\mathsf {fix}_{\gamma }(\phi )$ be the number of fixed points of the permutation 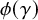 $\phi (\gamma )$. The function
$\phi (\gamma )$. The function 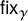 $\mathsf {fix}_{\gamma }$ is a special case of a natural family of functions on
$\mathsf {fix}_{\gamma }$ is a special case of a natural family of functions on 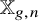 $\mathbb {X}_{g,n}$ called Wilson loops. Our new methodology leads to an asymptotic formula, as
$\mathbb {X}_{g,n}$ called Wilson loops. Our new methodology leads to an asymptotic formula, as 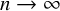 $n\to \infty $, for the expectation of
$n\to \infty $, for the expectation of 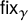 $\mathsf {fix}_{\gamma }$ with respect to the uniform probability measure on
$\mathsf {fix}_{\gamma }$ with respect to the uniform probability measure on 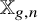 $\mathbb {X}_{g,n}$, which is denoted by
$\mathbb {X}_{g,n}$, which is denoted by 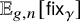 $\mathbb {E}_{g,n}[\mathsf {fix}_{\gamma }]$. We prove that if
$\mathbb {E}_{g,n}[\mathsf {fix}_{\gamma }]$. We prove that if 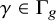 $\gamma \in \Gamma _{g}$ is not the identity and q is maximal such that
$\gamma \in \Gamma _{g}$ is not the identity and q is maximal such that 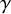 $\gamma $ is a qth power in
$\gamma $ is a qth power in 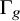 $\Gamma _{g}$, then
$\Gamma _{g}$, then 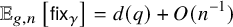 $$\begin{align*}\mathbb{E}_{g,n}\left[\mathsf{fix}_{\gamma}\right]=d(q)+O(n^{-1}) \end{align*}$$
$$\begin{align*}\mathbb{E}_{g,n}\left[\mathsf{fix}_{\gamma}\right]=d(q)+O(n^{-1}) \end{align*}$$as
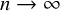 $n\to \infty $, where
$n\to \infty $, where 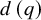 $d\left (q\right )$ is the number of divisors of q. Even the weaker corollary that
$d\left (q\right )$ is the number of divisors of q. Even the weaker corollary that 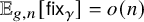 $\mathbb {E}_{g,n}[\mathsf {fix}_{\gamma }]=o(n)$ as
$\mathbb {E}_{g,n}[\mathsf {fix}_{\gamma }]=o(n)$ as 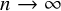 $n\to \infty $ is a new result of this paper. We also prove that
$n\to \infty $ is a new result of this paper. We also prove that 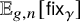 $\mathbb {E}_{g,n}[\mathsf {fix}_{\gamma }]$ can be approximated to any order
$\mathbb {E}_{g,n}[\mathsf {fix}_{\gamma }]$ can be approximated to any order 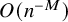 $O(n^{-M})$ by a polynomial in
$O(n^{-M})$ by a polynomial in 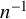 $n^{-1}$.
$n^{-1}$.
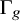
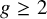
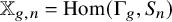
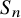

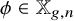
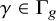
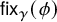
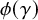
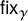
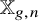
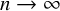
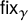
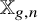
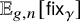
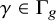
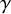
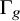
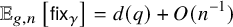
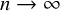
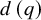
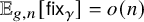
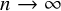
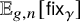
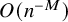
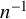
Strong Shannon–McMillan–Breiman’s theorem for locally compact groups
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 66 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 05 May 2023, pp. 1274-1279
- Print publication:
- December 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove that for a vast class of random walks on a compactly generated group, the exponential growth of convolutions of a probability density function along almost every sample path is bounded by the growth of the group. As an application, we show that the almost sure and
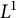 $L^1$ convergences of the Shannon–McMillan–Breiman theorem hold for compactly supported random walks on compactly generated groups with subexponential growth.
$L^1$ convergences of the Shannon–McMillan–Breiman theorem hold for compactly supported random walks on compactly generated groups with subexponential growth.
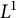
Large deviations of extremal eigenvalues of sample covariance matrices
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1275-1280
- Print publication:
- December 2023
-
- Article
- Export citation
-
Large deviations of the largest and smallest eigenvalues of
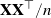 $\mathbf{X}\mathbf{X}^\top/n$ are studied in this note, where
$\mathbf{X}\mathbf{X}^\top/n$ are studied in this note, where 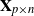 $\mathbf{X}_{p\times n}$ is a
$\mathbf{X}_{p\times n}$ is a 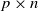 $p\times n$ random matrix with independent and identically distributed (i.i.d.) sub-Gaussian entries. The assumption imposed on the dimension size p and the sample size n is
$p\times n$ random matrix with independent and identically distributed (i.i.d.) sub-Gaussian entries. The assumption imposed on the dimension size p and the sample size n is 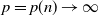 $p=p(n)\rightarrow\infty$ with
$p=p(n)\rightarrow\infty$ with 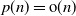 $p(n)={\mathrm{o}}(n)$. This study generalizes one result obtained in [3].
$p(n)={\mathrm{o}}(n)$. This study generalizes one result obtained in [3].
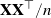
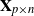
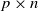
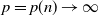
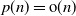
Abelian groups from random hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 20 April 2023, pp. 654-664
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For a
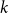 $k$-uniform hypergraph
$k$-uniform hypergraph 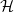 $\mathcal{H}$ on vertex set
$\mathcal{H}$ on vertex set 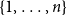 $\{1, \ldots, n\}$ we associate a particular signed incidence matrix
$\{1, \ldots, n\}$ we associate a particular signed incidence matrix 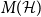 $M(\mathcal{H})$ over the integers. For
$M(\mathcal{H})$ over the integers. For 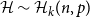 $\mathcal{H} \sim \mathcal{H}_k(n, p)$ an Erdős–Rényi random
$\mathcal{H} \sim \mathcal{H}_k(n, p)$ an Erdős–Rényi random 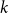 $k$-uniform hypergraph,
$k$-uniform hypergraph, 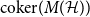 ${\mathrm{coker}}(M(\mathcal{H}))$ is then a model for random abelian groups. Motivated by conjectures from the study of random simplicial complexes we show that for
${\mathrm{coker}}(M(\mathcal{H}))$ is then a model for random abelian groups. Motivated by conjectures from the study of random simplicial complexes we show that for 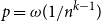 $p = \omega (1/n^{k - 1})$,
$p = \omega (1/n^{k - 1})$, 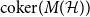 ${\mathrm{coker}}(M(\mathcal{H}))$ is torsion-free.
${\mathrm{coker}}(M(\mathcal{H}))$ is torsion-free.
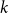
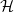
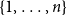
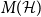
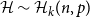
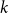
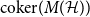
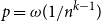
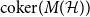
Asymptotic behaviour of the first positions of uniform parking functions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 20 April 2023, pp. 1201-1218
- Print publication:
- December 2023
-
- Article
- Export citation
-
In this paper we study the asymptotic behaviour of a random uniform parking function
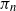 $\pi_n$ of size n. We show that the first
$\pi_n$ of size n. We show that the first 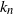 $k_n$ places
$k_n$ places 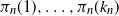 $\pi_n(1),\ldots,\pi_n(k_n)$ of
$\pi_n(1),\ldots,\pi_n(k_n)$ of 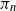 $\pi_n$ are asymptotically independent and identically distributed (i.i.d.) and uniform on
$\pi_n$ are asymptotically independent and identically distributed (i.i.d.) and uniform on 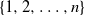 $\{1,2,\ldots,n\}$, for the total variation distance when
$\{1,2,\ldots,n\}$, for the total variation distance when 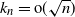 $k_n = {\rm{o}}(\sqrt{n})$, and for the Kolmogorov distance when
$k_n = {\rm{o}}(\sqrt{n})$, and for the Kolmogorov distance when 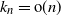 $k_n={\rm{o}}(n)$, improving results of Diaconis and Hicks. Moreover, we give bounds for the rate of convergence, as well as limit theorems for certain statistics such as the sum or the maximum of the first
$k_n={\rm{o}}(n)$, improving results of Diaconis and Hicks. Moreover, we give bounds for the rate of convergence, as well as limit theorems for certain statistics such as the sum or the maximum of the first 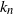 $k_n$ parking places. The main tool is a reformulation using conditioned random walks.
$k_n$ parking places. The main tool is a reformulation using conditioned random walks.
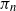
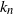
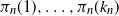
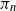
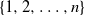
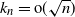
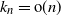
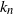
Local limits of spatial inhomogeneous random graphs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 14 April 2023, pp. 793-840
- Print publication:
- September 2023
-
- Article
- Export citation
-
Consider a set of n vertices, where each vertex has a location in
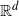 $\mathbb{R}^d$ that is sampled uniformly from the unit cube in
$\mathbb{R}^d$ that is sampled uniformly from the unit cube in 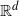 $\mathbb{R}^d$, and a weight associated to it. Construct a random graph by placing edges independently for each vertex pair with a probability that is a function of the distance between the locations and the vertex weights.
$\mathbb{R}^d$, and a weight associated to it. Construct a random graph by placing edges independently for each vertex pair with a probability that is a function of the distance between the locations and the vertex weights.Under appropriate integrability assumptions on the edge probabilities that imply sparseness of the model, after appropriately blowing up the locations, we prove that the local limit of this random graph sequence is the (countably) infinite random graph on
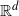 $\mathbb{R}^d$ with vertex locations given by a homogeneous Poisson point process, having weights which are independent and identically distributed copies of limiting vertex weights. Our set-up covers many sparse geometric random graph models from the literature, including geometric inhomogeneous random graphs (GIRGs), hyperbolic random graphs, continuum scale-free percolation, and weight-dependent random connection models.
$\mathbb{R}^d$ with vertex locations given by a homogeneous Poisson point process, having weights which are independent and identically distributed copies of limiting vertex weights. Our set-up covers many sparse geometric random graph models from the literature, including geometric inhomogeneous random graphs (GIRGs), hyperbolic random graphs, continuum scale-free percolation, and weight-dependent random connection models.We prove that the limiting degree distribution is mixed Poisson and the typical degree sequence is uniformly integrable, and we obtain convergence results on various measures of clustering in our graphs as a consequence of local convergence. Finally, as a byproduct of our argument, we prove a doubly logarithmic lower bound on typical distances in this general setting.
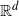
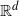
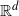
BERRY–ESSEEN BOUND AND LOCAL LIMIT THEOREM FOR THE COEFFICIENTS OF PRODUCTS OF RANDOM MATRICES
- Part of
-
- Journal:
- Journal of the Institute of Mathematics of Jussieu / Volume 23 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 07 December 2022, pp. 705-735
- Print publication:
- March 2024
-
- Article
- Export citation
-
Let
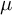 $\mu $ be a probability measure on
$\mu $ be a probability measure on 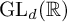 $\mathrm {GL}_d(\mathbb {R})$, and denote by
$\mathrm {GL}_d(\mathbb {R})$, and denote by 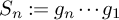 $S_n:= g_n \cdots g_1$ the associated random matrix product, where
$S_n:= g_n \cdots g_1$ the associated random matrix product, where 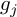 $g_j$ are i.i.d. with law
$g_j$ are i.i.d. with law 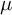 $\mu $. Under the assumptions that
$\mu $. Under the assumptions that 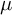 $\mu $ has a finite exponential moment and generates a proximal and strongly irreducible semigroup, we prove a Berry–Esseen bound with the optimal rate
$\mu $ has a finite exponential moment and generates a proximal and strongly irreducible semigroup, we prove a Berry–Esseen bound with the optimal rate 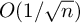 $O(1/\sqrt n)$ for the coefficients of
$O(1/\sqrt n)$ for the coefficients of 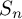 $S_n$, settling a long-standing question considered since the fundamental work of Guivarc’h and Raugi. The local limit theorem for the coefficients is also obtained, complementing a recent partial result of Grama, Quint and Xiao.
$S_n$, settling a long-standing question considered since the fundamental work of Guivarc’h and Raugi. The local limit theorem for the coefficients is also obtained, complementing a recent partial result of Grama, Quint and Xiao.
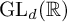
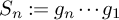
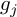
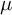
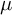
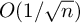
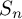
The natural extension of the random beta-transformation
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 43 / Issue 11 / November 2023
- Published online by Cambridge University Press:
- 04 November 2022, pp. 3861-3896
- Print publication:
- November 2023
-
- Article
- Export citation
-
We construct a geometrico-symbolic version of the natural extension of the random
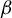 $\beta $-transformation introduced by Dajani and Kraaikamp [Random
$\beta $-transformation introduced by Dajani and Kraaikamp [Random 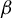 $\beta $-expansions. Ergod. Th. & Dynam. Sys. 23(2) (2003) 461–479]. This construction provides a new proof of the existence of a unique absolutely continuous invariant probability measure for the random
$\beta $-expansions. Ergod. Th. & Dynam. Sys. 23(2) (2003) 461–479]. This construction provides a new proof of the existence of a unique absolutely continuous invariant probability measure for the random 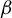 $\beta $-transformation, and an expression for its density. We then prove that this natural extension is a Bernoulli automorphism, generalizing to the random case the result of Smorodinsky [
$\beta $-transformation, and an expression for its density. We then prove that this natural extension is a Bernoulli automorphism, generalizing to the random case the result of Smorodinsky [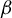 $\beta $-automorphisms are Bernoulli shifts. Acta Math. Acad. Sci. Hungar. 24 (1973), 273–278] about the greedy transformation.
$\beta $-automorphisms are Bernoulli shifts. Acta Math. Acad. Sci. Hungar. 24 (1973), 273–278] about the greedy transformation.
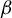
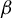
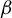
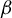
Rank-uniform local law for Wigner matrices
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 27 October 2022, e96
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A transport process on graphs and its limiting distributions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 10 October 2022, pp. 341-357
- Print publication:
- March 2023
-
- Article
- Export citation
-
Given a finite strongly connected directed graph
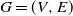 $G=(V, E)$, we study a Markov chain taking values on the space of probability measures on V. The chain, motivated by biological applications in the context of stochastic population dynamics, is characterized by transitions between states that respect the structure superimposed by E: mass (probability) can only be moved between neighbors in G. We provide conditions for the ergodicity of the chain. In a simple, symmetric case, we fully characterize the invariant probability.
$G=(V, E)$, we study a Markov chain taking values on the space of probability measures on V. The chain, motivated by biological applications in the context of stochastic population dynamics, is characterized by transitions between states that respect the structure superimposed by E: mass (probability) can only be moved between neighbors in G. We provide conditions for the ergodicity of the chain. In a simple, symmetric case, we fully characterize the invariant probability.
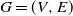
Sparse recovery properties of discrete random matrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 04 October 2022, pp. 316-325
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Motivated by problems from compressed sensing, we determine the threshold behaviour of a random
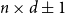 $n\times d \pm 1$ matrix
$n\times d \pm 1$ matrix  $M_{n,d}$ with respect to the property ‘every
$M_{n,d}$ with respect to the property ‘every  $s$ columns are linearly independent’. In particular, we show that for every
$s$ columns are linearly independent’. In particular, we show that for every 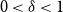 $0\lt \delta \lt 1$ and
$0\lt \delta \lt 1$ and 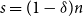 $s=(1-\delta )n$, if
$s=(1-\delta )n$, if 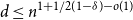 $d\leq n^{1+1/2(1-\delta )-o(1)}$ then with high probability every
$d\leq n^{1+1/2(1-\delta )-o(1)}$ then with high probability every  $s$ columns of
$s$ columns of 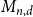 $M_{n,d}$ are linearly independent, and if
$M_{n,d}$ are linearly independent, and if 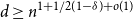 $d\geq n^{1+1/2(1-\delta )+o(1)}$ then with high probability there are some
$d\geq n^{1+1/2(1-\delta )+o(1)}$ then with high probability there are some  $s$ linearly dependent columns.
$s$ linearly dependent columns.
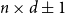


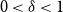
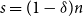
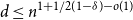

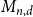
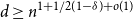

Exponential convergence to a quasi-stationary distribution for birth–death processes with an entrance boundary at infinity
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 10 August 2022, pp. 983-991
- Print publication:
- December 2022
-
- Article
- Export citation
-
We study the quasi-stationary behavior of the birth–death process with an entrance boundary at infinity. We give by the h-transform an alternative and simpler proof for the exponential convergence of conditioned distributions to a unique quasi-stationary distribution in the total variation norm. In addition, we also show that starting from any initial distribution the conditional probability converges to the unique quasi-stationary distribution exponentially fast in the
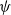 $\psi$-norm.
$\psi$-norm.
A unifying approach to non-minimal quasi-stationary distributions for one-dimensional diffusions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 08 August 2022, pp. 1106-1128
- Print publication:
- December 2022
-
- Article
- Export citation
On the moments of characteristic polynomials
- Part of
-
- Journal:
- Glasgow Mathematical Journal / Volume 65 / Issue S1 / May 2023
- Published online by Cambridge University Press:
- 05 August 2022, pp. S102-S122
- Print publication:
- May 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We calculate the moments of the characteristic polynomials of
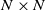 $N\times N$ matrices drawn from the Hermitian ensembles of Random Matrix Theory, at a position t in the bulk of the spectrum, as a series expansion in powers of t. We focus in particular on the Gaussian Unitary Ensemble. We employ a novel approach to calculate the coefficients in this series expansion of the moments, appropriately scaled. These coefficients are polynomials in N. They therefore grow as
$N\times N$ matrices drawn from the Hermitian ensembles of Random Matrix Theory, at a position t in the bulk of the spectrum, as a series expansion in powers of t. We focus in particular on the Gaussian Unitary Ensemble. We employ a novel approach to calculate the coefficients in this series expansion of the moments, appropriately scaled. These coefficients are polynomials in N. They therefore grow as 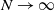 $N\to\infty$, meaning that in this limit the radius of convergence of the series expansion tends to zero. This is related to oscillations as t varies that are increasingly rapid as N grows. We show that the
$N\to\infty$, meaning that in this limit the radius of convergence of the series expansion tends to zero. This is related to oscillations as t varies that are increasingly rapid as N grows. We show that the 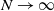 $N\to\infty$ asymptotics of the moments can be derived from this expansion when
$N\to\infty$ asymptotics of the moments can be derived from this expansion when 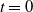 $t=0$. When
$t=0$. When 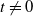 $t\ne 0$ we observe a surprising cancellation when the expansion coefficients for N and
$t\ne 0$ we observe a surprising cancellation when the expansion coefficients for N and 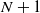 $N+1$ are formally averaged: this procedure removes all of the N-dependent terms leading to values that coincide with those expected on the basis of previously established asymptotic formulae for the moments. We obtain as well formulae for the expectation values of products of the secular coefficients.
$N+1$ are formally averaged: this procedure removes all of the N-dependent terms leading to values that coincide with those expected on the basis of previously established asymptotic formulae for the moments. We obtain as well formulae for the expectation values of products of the secular coefficients.
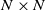
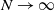
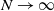
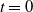
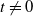
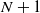
The hit-and-run version of top-to-random
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 12 July 2022, pp. 860-879
- Print publication:
- September 2022
-
- Article
- Export citation
-
We study an example of a hit-and-run random walk on the symmetric group
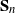 $\mathbf S_n$. Our starting point is the well-understood top-to-random shuffle. In the hit-and-run version, at each single step, after picking the point of insertion j uniformly at random in
$\mathbf S_n$. Our starting point is the well-understood top-to-random shuffle. In the hit-and-run version, at each single step, after picking the point of insertion j uniformly at random in 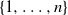 $\{1,\ldots,n\}$, the top card is inserted in the jth position k times in a row, where k is uniform in
$\{1,\ldots,n\}$, the top card is inserted in the jth position k times in a row, where k is uniform in 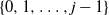 $\{0,1,\ldots,j-1\}$. The question is, does this accelerate mixing significantly or not? We show that, in
$\{0,1,\ldots,j-1\}$. The question is, does this accelerate mixing significantly or not? We show that, in 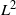 $L^2$ and sup-norm, this accelerates mixing at most by a constant factor (independent of n). Analyzing this problem in total variation is an interesting open question. We show that, in general, hit-and-run random walks on finite groups have non-negative spectrum.
$L^2$ and sup-norm, this accelerates mixing at most by a constant factor (independent of n). Analyzing this problem in total variation is an interesting open question. We show that, in general, hit-and-run random walks on finite groups have non-negative spectrum.
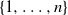
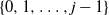
Spectral alignment of correlated Gaussian matrices
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 28 January 2022, pp. 279-310
- Print publication:
- March 2022
-
- Article
- Export citation
-
In this paper we analyze a simple spectral method (EIG1) for the problem of matrix alignment, consisting in aligning their leading eigenvectors: given two matrices A and B, we compute two corresponding leading eigenvectors
 $v_1$ and
$v_1$ and 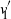 $v'_{\!\!1}$. The algorithm returns the permutation
$v'_{\!\!1}$. The algorithm returns the permutation 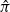 $\hat{\pi}$ such that the rank of coordinate
$\hat{\pi}$ such that the rank of coordinate 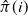 $\hat{\pi}(i)$ in
$\hat{\pi}(i)$ in 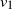 $v_1$ and that of coordinate i in
$v_1$ and that of coordinate i in 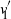 $v'_{\!\!1}$ (up to the sign of
$v'_{\!\!1}$ (up to the sign of 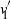 $v'_{\!\!1}$) are the same.
$v'_{\!\!1}$) are the same.We consider a model of weighted graphs where the adjacency matrix A belongs to the Gaussian orthogonal ensemble of size
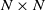 $N \times N$, and B is a noisy version of A where all nodes have been relabeled according to some planted permutation
$N \times N$, and B is a noisy version of A where all nodes have been relabeled according to some planted permutation 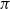 $\pi$; that is,
$\pi$; that is, 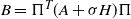 $B= \Pi^T (A+\sigma H) \Pi $, where
$B= \Pi^T (A+\sigma H) \Pi $, where 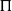 $\Pi$ is the permutation matrix associated with
$\Pi$ is the permutation matrix associated with 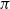 $\pi$ and H is an independent copy of A. We show the following zero–one law: with high probability, under the condition
$\pi$ and H is an independent copy of A. We show the following zero–one law: with high probability, under the condition 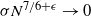 $\sigma N^{7/6+\epsilon} \to 0$ for some
$\sigma N^{7/6+\epsilon} \to 0$ for some 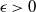 $\epsilon>0$, EIG1 recovers all but a vanishing part of the underlying permutation
$\epsilon>0$, EIG1 recovers all but a vanishing part of the underlying permutation 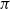 $\pi$, whereas if
$\pi$, whereas if 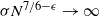 $\sigma N^{7/6-\epsilon} \to \infty$, this method cannot recover more than o(N) correct matches.
$\sigma N^{7/6-\epsilon} \to \infty$, this method cannot recover more than o(N) correct matches.This result gives an understanding of the simplest and fastest spectral method for matrix alignment (or complete weighted graph alignment), and involves proof methods and techniques which could be of independent interest.

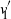
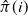
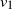
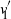
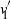
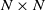
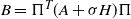
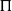
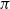
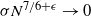
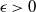
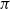
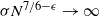
On model selection for dense stochastic block models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 14 January 2022, pp. 202-226
- Print publication:
- March 2022
-
- Article
- Export citation
SMALL-SCALE EQUIDISTRIBUTION OF RANDOM WAVES GENERATED BY AN UNFAIR COIN FLIP
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 114 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 29 November 2021, pp. 222-252
- Print publication:
- April 2023
-
- Article
- Export citation
-
In this paper we study the small-scale equidistribution property of random waves whose coefficients are determined by an unfair coin. That is, the coefficients take value
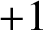 $+1$ with probability p and
$+1$ with probability p and 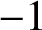 $-1$ with probability
$-1$ with probability 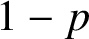 $1-p$. Random waves whose coefficients are associated with a fair coin are known to equidistribute down to the wavelength scale. We obtain explicit requirements on the deviation from the fair (
$1-p$. Random waves whose coefficients are associated with a fair coin are known to equidistribute down to the wavelength scale. We obtain explicit requirements on the deviation from the fair (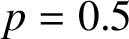 $p=0.5$) coin to retain equidistribution.
$p=0.5$) coin to retain equidistribution.
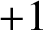
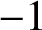
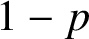
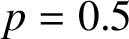
Large-deviation asymptotics of condition numbers of random matrices
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 22 November 2021, pp. 1114-1130
- Print publication:
- December 2021
-
- Article
- Export citation
-
Let
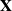 $\mathbf{X}$ be a
$\mathbf{X}$ be a 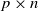 $p\times n$ random matrix whose entries are independent and identically distributed real random variables with zero mean and unit variance. We study the limiting behaviors of the 2-normal condition number k(p,n) of
$p\times n$ random matrix whose entries are independent and identically distributed real random variables with zero mean and unit variance. We study the limiting behaviors of the 2-normal condition number k(p,n) of 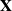 $\mathbf{X}$ in terms of large deviations for large n, with p being fixed or
$\mathbf{X}$ in terms of large deviations for large n, with p being fixed or 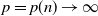 $p=p(n)\rightarrow\infty$ with
$p=p(n)\rightarrow\infty$ with 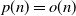 $p(n)=o(n)$. We propose two main ingredients: (i) to relate the large-deviation probabilities of k(p,n) to those involving n independent and identically distributed random variables, which enables us to consider a quite general distribution of the entries (namely the sub-Gaussian distribution), and (ii) to control, for standard normal entries, the upper tail of k(p,n) using the upper tails of ratios of two independent
$p(n)=o(n)$. We propose two main ingredients: (i) to relate the large-deviation probabilities of k(p,n) to those involving n independent and identically distributed random variables, which enables us to consider a quite general distribution of the entries (namely the sub-Gaussian distribution), and (ii) to control, for standard normal entries, the upper tail of k(p,n) using the upper tails of ratios of two independent 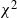 $\chi^2$ random variables, which enables us to establish an application in statistical inference.
$\chi^2$ random variables, which enables us to establish an application in statistical inference.
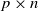
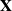
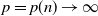
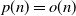
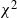
On the smallest singular value of symmetric random matrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 4 / July 2022
- Published online by Cambridge University Press:
- 05 November 2021, pp. 662-683
-
- Article
- Export citation
-
We show that for an
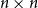 $n\times n$ random symmetric matrix
$n\times n$ random symmetric matrix 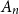 $A_n$, whose entries on and above the diagonal are independent copies of a sub-Gaussian random variable
$A_n$, whose entries on and above the diagonal are independent copies of a sub-Gaussian random variable 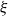 $\xi$ with mean 0 and variance 1, This improves a result of Vershynin, who obtained such a bound with
$\xi$ with mean 0 and variance 1, This improves a result of Vershynin, who obtained such a bound with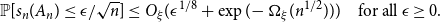 \begin{equation*}\mathbb{P}[s_n(A_n) \le \epsilon/\sqrt{n}] \le O_{\xi}(\epsilon^{1/8} + \exp(\!-\Omega_{\xi}(n^{1/2}))) \quad \text{for all } \epsilon \ge 0.\end{equation*}
\begin{equation*}\mathbb{P}[s_n(A_n) \le \epsilon/\sqrt{n}] \le O_{\xi}(\epsilon^{1/8} + \exp(\!-\Omega_{\xi}(n^{1/2}))) \quad \text{for all } \epsilon \ge 0.\end{equation*}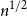 $n^{1/2}$ replaced by
$n^{1/2}$ replaced by 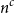 $n^{c}$ for a small constant c, and
$n^{c}$ for a small constant c, and 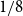 $1/8$ replaced by
$1/8$ replaced by 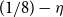 $(1/8) - \eta$ (with implicit constants also depending on
$(1/8) - \eta$ (with implicit constants also depending on 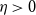 $\eta > 0$). Furthermore, when
$\eta > 0$). Furthermore, when 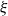 $\xi$ is a Rademacher random variable, we prove that The special case
$\xi$ is a Rademacher random variable, we prove that The special case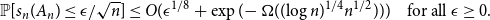 \begin{equation*}\mathbb{P}[s_n(A_n) \le \epsilon/\sqrt{n}] \le O(\epsilon^{1/8} + \exp(\!-\Omega((\!\log{n})^{1/4}n^{1/2}))) \quad \text{for all } \epsilon \ge 0.\end{equation*}
\begin{equation*}\mathbb{P}[s_n(A_n) \le \epsilon/\sqrt{n}] \le O(\epsilon^{1/8} + \exp(\!-\Omega((\!\log{n})^{1/4}n^{1/2}))) \quad \text{for all } \epsilon \ge 0.\end{equation*}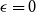 $\epsilon = 0$ improves a recent result of Campos, Mattos, Morris, and Morrison, which showed that
$\epsilon = 0$ improves a recent result of Campos, Mattos, Morris, and Morrison, which showed that 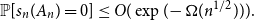 $\mathbb{P}[s_n(A_n) = 0] \le O(\exp(\!-\Omega(n^{1/2}))).$ Notably, in a departure from the previous two best bounds on the probability of singularity of symmetric matrices, which had relied on somewhat specialized and involved combinatorial techniques, our methods fall squarely within the broad geometric framework pioneered by Rudelson and Vershynin, and suggest the possibility of a principled geometric approach to the study of the singular spectrum of symmetric random matrices. The main innovations in our work are new notions of arithmetic structure – the Median Regularized Least Common Denominator (MRLCD) and the Median Threshold, which are natural refinements of the Regularized Least Common Denominator (RLCD)introduced by Vershynin, and should be more generally useful in contexts where one needs to combine anticoncentration information of different parts of a vector.
$\mathbb{P}[s_n(A_n) = 0] \le O(\exp(\!-\Omega(n^{1/2}))).$ Notably, in a departure from the previous two best bounds on the probability of singularity of symmetric matrices, which had relied on somewhat specialized and involved combinatorial techniques, our methods fall squarely within the broad geometric framework pioneered by Rudelson and Vershynin, and suggest the possibility of a principled geometric approach to the study of the singular spectrum of symmetric random matrices. The main innovations in our work are new notions of arithmetic structure – the Median Regularized Least Common Denominator (MRLCD) and the Median Threshold, which are natural refinements of the Regularized Least Common Denominator (RLCD)introduced by Vershynin, and should be more generally useful in contexts where one needs to combine anticoncentration information of different parts of a vector.