Refine listing
Actions for selected content:
1805 results in 05xxx
MINORS IN WEIGHTED GRAPHS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 77 / Issue 3 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 455-464
- Print publication:
- June 2008
-
- Article
-
- You have access
- Export citation
CUBIC EDGE-TRANSITIVE GRAPHS OF ORDER 8p2
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 77 / Issue 2 / April 2008
- Published online by Cambridge University Press:
- 01 April 2008, pp. 315-323
- Print publication:
- April 2008
-
- Article
-
- You have access
- Export citation
NEIGHBOURHOODS OF INDEPENDENT SETS FOR (a,b,k)-CRITICAL GRAPHS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 77 / Issue 2 / April 2008
- Published online by Cambridge University Press:
- 01 April 2008, pp. 277-283
- Print publication:
- April 2008
-
- Article
-
- You have access
- Export citation
A NOTE ON THE HU–HWANG–WANG CONJECTURE FOR GROUP TESTING
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 49 / Issue 4 / April 2008
- Published online by Cambridge University Press:
- 01 April 2008, pp. 561-571
-
- Article
-
- You have access
- Export citation
On the number of jumps of random walks with a barrier
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 1 / March 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 206-228
- Print publication:
- March 2008
-
- Article
-
- You have access
- Export citation
-
Let S 0 := 0 and Sk := ξ 1 + ··· + ξk for k ∈ ℕ := {1, 2, …}, where {ξk : k ∈ ℕ} are independent copies of a random variable ξ with values in ℕ and distribution pk := P{ξ = k}, k ∈ ℕ. We interpret the random walk {Sk : k = 0, 1, 2, …} as a particle jumping to the right through integer positions. Fix n ∈ ℕ and modify the process by requiring that the particle is bumped back to its current state each time a jump would bring the particle to a state larger than or equal to n. This constraint defines an increasing Markov chain {Rk (n) : k = 0, 1, 2, …} which never reaches the state n. We call this process a random walk with barrier n. Let Mn denote the number of jumps of the random walk with barrier n. This paper focuses on the asymptotics of Mn as n tends to ∞. A key observation is that, under p 1 > 0, {Mn : n ∈ ℕ} satisfies the distributional recursion M 1 = 0 and
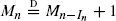 for n = 2, 3, …, where In is independent of M 2, …, M n−1 with distribution P{In = k} = pk / (p 1 + ··· + p n−1), k ∈ {1, …, n − 1}. Depending on the tail behavior of the distribution of ξ, several scalings for Mn and corresponding limiting distributions come into play, including stable distributions and distributions of exponential integrals of subordinators. The methods used in this paper are mainly probabilistic. The key tool is to compare (couple) the number of jumps, Mn , with the first time, Nn , when the unrestricted random walk {Sk : k = 0, 1, …} reaches a state larger than or equal to n. The results are applied to derive the asymptotics of the number of collision events (that take place until there is just a single block) for β(a, b)-coalescent processes with parameters 0 < a < 2 and b = 1.
for n = 2, 3, …, where In is independent of M 2, …, M n−1 with distribution P{In = k} = pk / (p 1 + ··· + p n−1), k ∈ {1, …, n − 1}. Depending on the tail behavior of the distribution of ξ, several scalings for Mn and corresponding limiting distributions come into play, including stable distributions and distributions of exponential integrals of subordinators. The methods used in this paper are mainly probabilistic. The key tool is to compare (couple) the number of jumps, Mn , with the first time, Nn , when the unrestricted random walk {Sk : k = 0, 1, …} reaches a state larger than or equal to n. The results are applied to derive the asymptotics of the number of collision events (that take place until there is just a single block) for β(a, b)-coalescent processes with parameters 0 < a < 2 and b = 1.
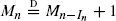 for
for Local properties of random mappings with exchangeable in-degrees
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 1 / March 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 183-205
- Print publication:
- March 2008
-
- Article
-
- You have access
- Export citation
-
In this paper we investigate the ‘local’ properties of a random mapping model, T n D̂, which maps the set {1, 2, …, n} into itself. The random mapping T n D̂ , which was introduced in a companion paper (Hansen and Jaworski (2008)), is constructed using a collection of exchangeable random variables D̂ 1, …, D̂ n which satisfy
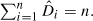 In the random digraph, G n D̂ , which represents the mapping T n D̂ , the in-degree sequence for the vertices is given by the variables D̂ 1, D̂ 2, …, D̂ n , and, in some sense, G n D̂ can be viewed as an analogue of the general independent degree models from random graph theory. By local properties we mean the distributions of random mapping characteristics related to a given vertex v of G n D̂ - for example, the numbers of predecessors and successors of v in G n D̂ . We show that the distribution of several variables associated with the local structure of G n D̂ can be expressed in terms of expectations of simple functions of D̂ 1, D̂ 2, …, D̂ n . We also consider two special examples of T n D̂ which correspond to random mappings with preferential and anti-preferential attachment, and determine, for these examples, exact and asymptotic distributions for the local structure variables considered in this paper. These distributions are also of independent interest.
In the random digraph, G n D̂ , which represents the mapping T n D̂ , the in-degree sequence for the vertices is given by the variables D̂ 1, D̂ 2, …, D̂ n , and, in some sense, G n D̂ can be viewed as an analogue of the general independent degree models from random graph theory. By local properties we mean the distributions of random mapping characteristics related to a given vertex v of G n D̂ - for example, the numbers of predecessors and successors of v in G n D̂ . We show that the distribution of several variables associated with the local structure of G n D̂ can be expressed in terms of expectations of simple functions of D̂ 1, D̂ 2, …, D̂ n . We also consider two special examples of T n D̂ which correspond to random mappings with preferential and anti-preferential attachment, and determine, for these examples, exact and asymptotic distributions for the local structure variables considered in this paper. These distributions are also of independent interest.
 In the random digraph,
In the random digraph, Bisymmetric functions, Macdonald polynomials and
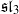 basic hypergeometric series
basic hypergeometric series
- Part of
-
- Journal:
- Compositio Mathematica / Volume 144 / Issue 2 / March 2008
- Published online by Cambridge University Press:
- 01 March 2008, pp. 271-303
- Print publication:
- March 2008
-
- Article
-
- You have access
- Export citation
-
A new type of
basic hypergeometric series based on Macdonald polynomials is introduced. Besides a pair of Macdonald polynomials attached to two different sets of variables, a key ingredient in the basic hypergeometric series is a bisymmetric function related to Macdonald’s commuting family of q-difference operators, to the Selberg integrals of Tarasov and Varchenko, and to alternating sign matrices. Our main result for series is a multivariable generalization of the celebrated q-binomial theorem. In the limit this q-binomial sum yields a new Selberg integral for Jack polynomials.
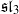 basic hypergeometric series
basic hypergeometric series
INDECOMPOSABILITY GRAPHS OF RINGS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 77 / Issue 1 / February 2008
- Published online by Cambridge University Press:
- 01 February 2008, pp. 151-159
- Print publication:
- February 2008
-
- Article
-
- You have access
- Export citation
On the connectivity and diameter of small-world networks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 39 / Issue 4 / December 2007
- Published online by Cambridge University Press:
- 01 July 2016, pp. 853-863
- Print publication:
- December 2007
-
- Article
-
- You have access
- Export citation
Graphs with specified degree distributions, simple epidemics, and local vaccination strategies
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 39 / Issue 4 / December 2007
- Published online by Cambridge University Press:
- 01 July 2016, pp. 922-948
- Print publication:
- December 2007
-
- Article
-
- You have access
- Export citation
Counterexamples to Okounkov’s log-concavity conjecture
- Part of
-
- Journal:
- Compositio Mathematica / Volume 143 / Issue 6 / November 2007
- Published online by Cambridge University Press:
- 01 November 2007, pp. 1545-1557
- Print publication:
- November 2007
-
- Article
-
- You have access
- Export citation
CLT-related large deviation bounds based on Stein's method
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 39 / Issue 3 / September 2007
- Published online by Cambridge University Press:
- 01 July 2016, pp. 731-752
- Print publication:
- September 2007
-
- Article
-
- You have access
- Export citation
Coupling of Two SIR Epidemic Models with Variable Susceptibilities and Infectivities
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 41-57
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
Large Deviations Principle for Occupancy Problems with Colored Balls
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 115-141
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
On the asymptotic behaviour of random recursive trees in random environments
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 38 / Issue 4 / December 2006
- Published online by Cambridge University Press:
- 08 September 2016, pp. 1047-1070
- Print publication:
- December 2006
-
- Article
-
- You have access
- Export citation
An urn model arising from all-optical networks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 4 / December 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 952-966
- Print publication:
- December 2006
-
- Article
-
- You have access
- Export citation
Large deviations-based upper bounds on the expected relative length of longest common subsequences
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 38 / Issue 3 / September 2006
- Published online by Cambridge University Press:
- 01 July 2016, pp. 827-852
- Print publication:
- September 2006
-
- Article
-
- You have access
- Export citation
Efficient routeing in Poisson small-world networks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 3 / September 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 678-686
- Print publication:
- September 2006
-
- Article
-
- You have access
- Export citation
Ultra-small scale-free geometric networks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 3 / September 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 665-677
- Print publication:
- September 2006
-
- Article
-
- You have access
- Export citation
Parallel matching for ranking all teams in a tournament
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 38 / Issue 3 / September 2006
- Published online by Cambridge University Press:
- 01 July 2016, pp. 804-826
- Print publication:
- September 2006
-
- Article
-
- You have access
- Export citation
