Refine listing
Actions for selected content:
1070 results in 60Fxx
A functional central limit theorem for a random ledger model
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 20 July 2026, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lower deviations for branching processes with immigration
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 10 July 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
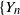 $\{Y_{n}$,
$\{Y_{n}$, 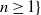 $n \geq 1\}$ be a critical branching process with immigration having finite variance for the offspring number of particles and finite mean for the immigrating number of particles. In this paper we study lower deviation probabilities for
$n \geq 1\}$ be a critical branching process with immigration having finite variance for the offspring number of particles and finite mean for the immigrating number of particles. In this paper we study lower deviation probabilities for 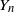 $Y_{n}$. More precisely, assuming that
$Y_{n}$. More precisely, assuming that 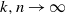 $k,n \to \infty$ so that
$k,n \to \infty$ so that 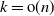 $k={\mathrm{o}} (n)$, we investigate the asymptotics of
$k={\mathrm{o}} (n)$, we investigate the asymptotics of 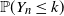 $\mathbb P(Y_{n} \leq k )$ and
$\mathbb P(Y_{n} \leq k )$ and 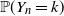 $\mathbb P(Y_{n} = k )$. Our results clarify the role of the moment conditions in the local limit theorem for
$\mathbb P(Y_{n} = k )$. Our results clarify the role of the moment conditions in the local limit theorem for 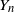 $Y_n$ proved by Mellein (1982).
$Y_n$ proved by Mellein (1982).
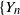
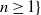
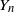
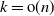
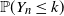
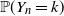
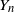
Aggregating heavy-tailed random vectors: from finite sums to lévy processes
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 18 June 2026, pp. 1-44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The tail behavior of aggregates of heavy-tailed random vectors is known to be determined by the so-called principle of ‘one large jump’, be it for finite sums, random sums, or Lévy processes. We establish that, in fact, a more general principle is at play. Assuming that the random vectors are multivariate regularly varying on various subcones of the positive orthant
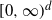 $[0,\infty)^d$, first we show that their aggregates are also multivariate regularly varying on these subcones. This allows us to approximate certain tail probabilities rendered asymptotically negligible under classical regular variation. Second, we discover that depending on the structure of a particular tail event, the tail behavior of the aggregates may be characterized by more than a single large jump. Finally, we illustrate a similar phenomenon for regularly varying multivariate Lévy processes, establishing as well a relationship between regular variation of a multivariate Lévy process and multivariate regular variation of its Lévy measure on different subcones. The applicability of these results in financial and insurance risk management is discussed.
$[0,\infty)^d$, first we show that their aggregates are also multivariate regularly varying on these subcones. This allows us to approximate certain tail probabilities rendered asymptotically negligible under classical regular variation. Second, we discover that depending on the structure of a particular tail event, the tail behavior of the aggregates may be characterized by more than a single large jump. Finally, we illustrate a similar phenomenon for regularly varying multivariate Lévy processes, establishing as well a relationship between regular variation of a multivariate Lévy process and multivariate regular variation of its Lévy measure on different subcones. The applicability of these results in financial and insurance risk management is discussed.
On the number of crossings and bouncings of a diffusion at a sticky threshold
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 28 May 2026, pp. 1-27
-
- Article
-
- You have access
- HTML
- Export citation
Functional limit theorems for branching processes in a nearly degenerate varying environment
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 20 May 2026, pp. 1-20
-
- Article
- Export citation
-
We investigate branching processes in a nearly degenerate varying environment, where the offspring distribution converges to the degenerate distribution at 1. Such processes die out almost surely; therefore, we either condition on non-extinction or add inhomogeneous immigration. Extending our one-dimensional limit results from Kevei and Kubatovics (2024), we derive functional limit theorems. In the former case, the limit process is a time-changed simple birth-and-death process on
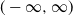 $(-\infty, \infty)$ conditioned on survival at 0, while in the latter, it is a time-changed stationary continuous-time Markov branching process with immigration.
$(-\infty, \infty)$ conditioned on survival at 0, while in the latter, it is a time-changed stationary continuous-time Markov branching process with immigration.
On McKean–Vlasov branching diffusion processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 15 May 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Local limit theorems for energy fluxes of infinitely divisible random fields
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 04 May 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Remarks on Kolmogorov’s constant for simple branching processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 28 April 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Recent investigations have argued that there is a simple explicit representation for the Kolmogorov constant c associated with the subcritical Galton–Watson branching process. We exhibit examples showing that although this representation can be valid, it more often is not. Our work is presented in terms of the limiting conditional mean population size
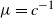 $\mu=c^{-1}$. The analogous quantity for the Markov branching process is denoted by
$\mu=c^{-1}$. The analogous quantity for the Markov branching process is denoted by 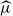 $\widehat\mu$. We show that the simple representation put forward for
$\widehat\mu$. We show that the simple representation put forward for 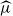 $\widehat\mu$ in fact is an upper bound that is attained only if the offspring-number probability-generating function is quadratic. The conditional mean
$\widehat\mu$ in fact is an upper bound that is attained only if the offspring-number probability-generating function is quadratic. The conditional mean 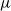 $\mu$ is the limit of a computable increasing sequence
$\mu$ is the limit of a computable increasing sequence 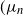 $(\mu_n$). Estimates of n are determined ensuring that, for any small positive number
$(\mu_n$). Estimates of n are determined ensuring that, for any small positive number  $\varepsilon$,
$\varepsilon$, 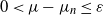 $0\lt\mu-\mu_n\le \varepsilon$.
$0\lt\mu-\mu_n\le \varepsilon$.
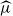
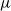
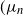

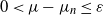
Existence of large deviations rate function for any S-unimodal map
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems , First View
- Published online by Cambridge University Press:
- 24 April 2026, pp. 1-48
-
- Article
- Export citation
Strong uniform convergence of Laplacians of random geometric and directed kNN graphs on compact manifolds
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 24 April 2026, pp. 1-36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Consider n points independently sampled from a density p of class
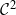 $\mathcal{C}^2$ on a smooth compact d-dimensional submanifold
$\mathcal{C}^2$ on a smooth compact d-dimensional submanifold 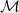 $\mathcal{M}$ of
$\mathcal{M}$ of 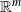 $\mathbb{R}^m$, and consider the random walk visiting these points according to a transition kernel K. We study the almost sure uniform convergence of the generator of this process to the diffusive Laplace–Beltrami operator when n tends to infinity, from which we establish the convergence of the random walk to a diffusion process on the manifold. In contrast to known results, our result does not require the kernel K to be continuous, which covers the cases of walks exploring k-nearest neighbor (kNN) and geometric graphs, and convergence rates are given. The distance between the random walk generator and the limiting operator is separated into several terms: a statistical term, related to the law of large numbers, is treated with concentration tools and an approximation term that we control with tools from differential geometry. The case of kNN Laplacians is detailed. The convergence of the stochastic processes having these operators as generators is also studied, by establishing additional tightness results of their distributions on the space of càdlàg functions.
$\mathbb{R}^m$, and consider the random walk visiting these points according to a transition kernel K. We study the almost sure uniform convergence of the generator of this process to the diffusive Laplace–Beltrami operator when n tends to infinity, from which we establish the convergence of the random walk to a diffusion process on the manifold. In contrast to known results, our result does not require the kernel K to be continuous, which covers the cases of walks exploring k-nearest neighbor (kNN) and geometric graphs, and convergence rates are given. The distance between the random walk generator and the limiting operator is separated into several terms: a statistical term, related to the law of large numbers, is treated with concentration tools and an approximation term that we control with tools from differential geometry. The case of kNN Laplacians is detailed. The convergence of the stochastic processes having these operators as generators is also studied, by establishing additional tightness results of their distributions on the space of càdlàg functions.
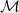
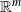
FRACTAL UNCERTAINTY PRINCIPLE FOR RANDOM CANTOR SETS
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society , First View
- Published online by Cambridge University Press:
- 13 April 2026, pp. 1-22
-
- Article
- Export citation
-
We continue our investigation of the fractal uncertainty principle (FUP) for random fractal sets. In the prequel Eswarathasan and Han [‘Fractal uncertainty principle for discrete Cantor sets with random alphabet’, Math. Res. Lett. 30(6) (2023), 1657–1679], we considered the Cantor sets in the discrete setting with alphabets randomly chosen from a base of digits so the dimension
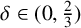 $\delta \in (0,\frac 23)$. We proved that, with overwhelming probability, the FUP with an exponent
$\delta \in (0,\frac 23)$. We proved that, with overwhelming probability, the FUP with an exponent 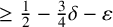 $\ge \frac 12-\frac 34\delta -\varepsilon $ holds for these discrete Cantor sets with random alphabets. In this paper, we construct random Cantor sets with dimension
$\ge \frac 12-\frac 34\delta -\varepsilon $ holds for these discrete Cantor sets with random alphabets. In this paper, we construct random Cantor sets with dimension  $\delta \in (0,\frac 23)$ in
$\delta \in (0,\frac 23)$ in 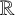 $\mathbb {R}$ via a different random procedure from the previous one used in Eswarathasan and Han [‘Fractal uncertainty principle for discrete Cantor sets with random alphabet’, Math. Res. Lett. 30(6) (2023), 1657–1679]. We prove that, with overwhelming probability, the FUP with an exponent
$\mathbb {R}$ via a different random procedure from the previous one used in Eswarathasan and Han [‘Fractal uncertainty principle for discrete Cantor sets with random alphabet’, Math. Res. Lett. 30(6) (2023), 1657–1679]. We prove that, with overwhelming probability, the FUP with an exponent  $\ge \frac 12-\frac 34\delta -\varepsilon $ holds. The proof follows from establishing a Fourier decay estimate of the corresponding random Cantor measures, which is in turn based on a concentration of measure phenomenon in an appropriate probability space for the random Cantor sets.
$\ge \frac 12-\frac 34\delta -\varepsilon $ holds. The proof follows from establishing a Fourier decay estimate of the corresponding random Cantor measures, which is in turn based on a concentration of measure phenomenon in an appropriate probability space for the random Cantor sets.
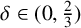
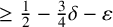


Asymptotic normality for triangle counting in the sparse
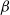 $\beta$-model
$\beta$-model
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the number of triangles
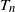 $T_n$ in the sparse
$T_n$ in the sparse 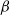 $\beta$-model on n vertices, a random graph model that captures degree heterogeneity in real-world networks. Using the norms of the heterogeneity parameter vector, we first determine the asymptotic mean and variance of
$\beta$-model on n vertices, a random graph model that captures degree heterogeneity in real-world networks. Using the norms of the heterogeneity parameter vector, we first determine the asymptotic mean and variance of 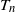 $T_n$. Next, by applying the Malliavin–Stein method, we derive a non-asymptotic upper bound on the Kolmogorov distance between the normalized
$T_n$. Next, by applying the Malliavin–Stein method, we derive a non-asymptotic upper bound on the Kolmogorov distance between the normalized 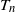 $T_n$ and the standard normal distribution. Under an additional assumption on degree heterogeneity, we further prove the asymptotic normality for
$T_n$ and the standard normal distribution. Under an additional assumption on degree heterogeneity, we further prove the asymptotic normality for 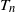 $T_n$ as
$T_n$ as 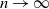 $n\to\infty$.
$n\to\infty$.
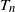
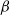
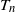
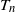
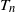
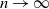
Weak convergence of the integral of semi-Markov processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the asymptotic properties, in the weak sense, of regenerative processes and Markov renewal processes. For the latter, we derive both renewal-type results, also concerning the related counting process, and ergodic-type results, including the so-called
 $\varphi$-mixing property. This theoretical framework permits us to study the weak limit of the integral of a semi-Markov process, which can be interpreted as the position of a particle moving with finite velocities, taken for a random time according to the Markov renewal process underlying the semi-Markov one. Under mild conditions, we obtain the weak convergence to scaled Brownian motion. As a particular case, this result establishes the weak convergence of the classical generalized telegraph process.
$\varphi$-mixing property. This theoretical framework permits us to study the weak limit of the integral of a semi-Markov process, which can be interpreted as the position of a particle moving with finite velocities, taken for a random time according to the Markov renewal process underlying the semi-Markov one. Under mild conditions, we obtain the weak convergence to scaled Brownian motion. As a particular case, this result establishes the weak convergence of the classical generalized telegraph process.

Large deviations for Cox–ingersoll–ross processes with state-dependent fast switching
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 26 March 2026, pp. 1-34
-
- Article
- Export citation
-
We study large deviations for Cox–Ingersoll–Ross processes with small noise and state-dependent fast switching via associated Hamilton–Jacobi–Bellman equations. As time scales separate, when the noise goes to 0 and the rate of switching goes to
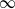 $\infty$, we get a limit equation characterized by the averaging principle. Moreover, we prove the large deviation principle with an action-integral form rate function to describe the asymptotic behavior of such systems. The new ingredient is establishing the comparison principle in the singular context. The proof is carried out using the nonlinear semigroup method from Feng and Kurtz’s book [14].
$\infty$, we get a limit equation characterized by the averaging principle. Moreover, we prove the large deviation principle with an action-integral form rate function to describe the asymptotic behavior of such systems. The new ingredient is establishing the comparison principle in the singular context. The proof is carried out using the nonlinear semigroup method from Feng and Kurtz’s book [14].
Monochromatic subgraphs in randomly colored dense multiplex networks
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-36
-
- Article
- Export citation
-
Given a sequence of graphs
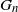 $G_n$ and a fixed graph H, denote by
$G_n$ and a fixed graph H, denote by 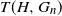 $T(H, G_n)$ the number of monochromatic copies of the graph H in a uniformly random c-coloring of the vertices of
$T(H, G_n)$ the number of monochromatic copies of the graph H in a uniformly random c-coloring of the vertices of 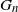 $G_n$. In this paper we study the joint distribution of a finite collection of monochromatic graph counts in networks with multiple layers (multiplex networks). Specifically, given a finite collection of graphs
$G_n$. In this paper we study the joint distribution of a finite collection of monochromatic graph counts in networks with multiple layers (multiplex networks). Specifically, given a finite collection of graphs 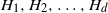 $H_1, H_2, \ldots, H_d$ we derive the joint distribution of
$H_1, H_2, \ldots, H_d$ we derive the joint distribution of 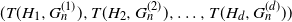 $(T(H_1, G_n^{(1)}), T(H_2, G_n^{(2)}), \ldots, T(H_d, G_n^{(d)}))$, where
$(T(H_1, G_n^{(1)}), T(H_2, G_n^{(2)}), \ldots, T(H_d, G_n^{(d)}))$, where 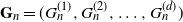 $\mathbf{G}_n = (G_n^{(1)}, G_n^{(2)}, \ldots, G_n^{(d)})$ is a collection of dense graphs on the same vertex set converging in the multiplex cut-metric. The limiting distribution is the sum of two independent components: a multivariate Gaussian and a sum of independent bivariate stochastic integrals. This extends previous results on the marginal convergence of monochromatic subgraphs in a sequence of graphs to the joint convergence of a finite collection of monochromatic subgraphs in a sequence of multiplex networks. Several applications and examples are discussed.
$\mathbf{G}_n = (G_n^{(1)}, G_n^{(2)}, \ldots, G_n^{(d)})$ is a collection of dense graphs on the same vertex set converging in the multiplex cut-metric. The limiting distribution is the sum of two independent components: a multivariate Gaussian and a sum of independent bivariate stochastic integrals. This extends previous results on the marginal convergence of monochromatic subgraphs in a sequence of graphs to the joint convergence of a finite collection of monochromatic subgraphs in a sequence of multiplex networks. Several applications and examples are discussed.
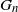
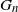
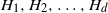
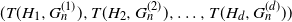
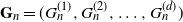
On asymptotic behavior of time of extinction of critical bisexual branching process in random environment
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-13
-
- Article
- Export citation
-
We consider a critical bisexual branching process in a random environment generated by independent and identically distributed random variables. Assuming that the process starts with a large number of pairs N, we prove that its extinction time is of order
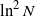 $\ln^2 N$. Interestingly, this result is valid for a general class of mating functions. Among these are the functions describing the monogamous and polygamous behavior of couples, as well as the function reducing the bisexual branching process to the simple one.
$\ln^2 N$. Interestingly, this result is valid for a general class of mating functions. Among these are the functions describing the monogamous and polygamous behavior of couples, as well as the function reducing the bisexual branching process to the simple one.
Self-normalized Cramér-type moderate deviation of stochastic gradient Langevin dynamics
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The limiting spectral distribution of the noncentral unified matrix model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 20 February 2026, pp. 772-787
- Print publication:
- June 2026
-
- Article
- Export citation
-
We investigate the limiting spectral distribution of a noncentral unified matrix model defined by
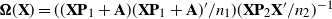 $\boldsymbol{\Omega}(\mathbf{X}) = ({(\mathbf{X}\mathbf{P}_1+\mathbf{A})(\mathbf{X}\mathbf{P}_1+\mathbf{A})'}/{n_1}) ({\mathbf{X}\mathbf{P}_2\mathbf{X}'}/{n_2})^{-1}$, where
$\boldsymbol{\Omega}(\mathbf{X}) = ({(\mathbf{X}\mathbf{P}_1+\mathbf{A})(\mathbf{X}\mathbf{P}_1+\mathbf{A})'}/{n_1}) ({\mathbf{X}\mathbf{P}_2\mathbf{X}'}/{n_2})^{-1}$, where 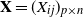 $\mathbf{X}=(X_{ij})_{p\times n}$ is a random matrix with independent and identically distributed real entries having zero mean and finite second moment.
$\mathbf{X}=(X_{ij})_{p\times n}$ is a random matrix with independent and identically distributed real entries having zero mean and finite second moment. 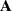 $\mathbf{A}$ is a
$\mathbf{A}$ is a 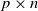 $p\times n$ nonrandom matrix. The matrices
$p\times n$ nonrandom matrix. The matrices 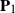 $\mathbf{P}_1$ and
$\mathbf{P}_1$ and 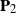 $\mathbf{P}_2$ are projection matrices satisfying
$\mathbf{P}_2$ are projection matrices satisfying 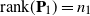 $\mathrm{rank}(\mathbf{P}_1)=n_1$,
$\mathrm{rank}(\mathbf{P}_1)=n_1$, 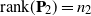 $\mathrm{rank}(\mathbf{P}_2)=n_2$, and
$\mathrm{rank}(\mathbf{P}_2)=n_2$, and 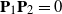 $\mathbf{P}_1\mathbf{P}_2=0$. When
$\mathbf{P}_1\mathbf{P}_2=0$. When 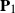 $\mathbf{P}_1$ and
$\mathbf{P}_1$ and 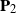 $\mathbf{P}_2$ are random, they are assumed to be independent of
$\mathbf{P}_2$ are random, they are assumed to be independent of 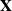 $\mathbf{X}$. When
$\mathbf{X}$. When 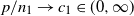 $p/n_1\to c_1\in(0,\infty)$ and
$p/n_1\to c_1\in(0,\infty)$ and 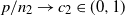 $p/n_2\to c_2\in(0,1)$, we establish the almost sure convergence of the empirical spectral distribution of
$p/n_2\to c_2\in(0,1)$, we establish the almost sure convergence of the empirical spectral distribution of 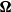 $\boldsymbol{\Omega}$ to a deterministic limiting distribution. Furthermore, we show that this limiting distribution coincides with that of the noncentral F-matrix, thus revealing a deep connection between the proposed model and classical multivariate analysis.
$\boldsymbol{\Omega}$ to a deterministic limiting distribution. Furthermore, we show that this limiting distribution coincides with that of the noncentral F-matrix, thus revealing a deep connection between the proposed model and classical multivariate analysis.
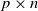
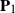
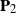
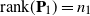
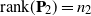
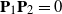
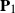
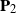
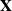
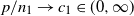
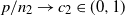
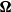
Forest fire model on
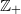 $\mathbb{Z}_+$ with delays
$\mathbb{Z}_+$ with delays
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 02 February 2026, pp. 116-134
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a generalization of the forest fire model on
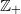 $\mathbb{Z}_+$ with ignition at zero only, studied by Volkov (2009 ALEA 6, 399–414). Unlike that model, we allow delays in the spread of the fires and the non-zero burning time of individual ‘trees’. We obtain some general properties for this model, which cover, among others, the phenomenon of an ‘infinite fire’, not present in the original model.
$\mathbb{Z}_+$ with ignition at zero only, studied by Volkov (2009 ALEA 6, 399–414). Unlike that model, we allow delays in the spread of the fires and the non-zero burning time of individual ‘trees’. We obtain some general properties for this model, which cover, among others, the phenomenon of an ‘infinite fire’, not present in the original model.
Some stability results of optimal investment in an Itô–Markov additive market
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 2 / June 2026
- Published online by Cambridge University Press:
- 23 January 2026, pp. 811-827
- Print publication:
- June 2026
-
- Article
- Export citation
