Refine listing
Actions for selected content:
22 results in RSS Journal Articles Collection
A BK inequality for random matchings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 22 July 2022, pp. 151-157
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
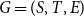 $G=(S,T,E)$ be a bipartite graph. For a matching
$G=(S,T,E)$ be a bipartite graph. For a matching 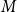 $M$ of
$M$ of 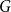 $G$, let
$G$, let 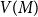 $V(M)$ be the set of vertices covered by
$V(M)$ be the set of vertices covered by 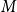 $M$, and let
$M$, and let 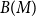 $B(M)$ be the symmetric difference of
$B(M)$ be the symmetric difference of 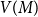 $V(M)$ and
$V(M)$ and 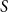 $S$. We prove that if
$S$. We prove that if 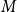 $M$ is a uniform random matching of
$M$ is a uniform random matching of 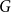 $G$, then
$G$, then 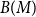 $B(M)$ satisfies the BK inequality for increasing events.
$B(M)$ satisfies the BK inequality for increasing events.
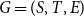
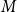
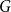
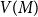
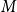
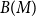
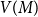
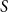
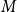
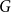
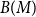
Calabi–Yau properties of Postnikov diagrams
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 21 July 2022, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that the dimer algebra of a connected Postnikov diagram in the disc is bimodule internally
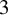 $3$-Calabi–Yau in the sense of the author’s earlier work [43]. As a consequence, we obtain an additive categorification of the cluster algebra associated to the diagram, which (after inverting frozen variables) is isomorphic to the homogeneous coordinate ring of a positroid variety in the Grassmannian by a recent result of Galashin and Lam [18]. We show that our categorification can be realised as a full extension closed subcategory of Jensen–King–Su’s Grassmannian cluster category [28], in a way compatible with their bijection between rank
$3$-Calabi–Yau in the sense of the author’s earlier work [43]. As a consequence, we obtain an additive categorification of the cluster algebra associated to the diagram, which (after inverting frozen variables) is isomorphic to the homogeneous coordinate ring of a positroid variety in the Grassmannian by a recent result of Galashin and Lam [18]. We show that our categorification can be realised as a full extension closed subcategory of Jensen–King–Su’s Grassmannian cluster category [28], in a way compatible with their bijection between rank 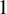 $1$ modules and Plücker coordinates.
$1$ modules and Plücker coordinates.
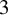
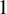
On local weak limit and subgraph counts for sparse random graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 July 2022, pp. 755-776
- Print publication:
- September 2022
-
- Article
- Export citation
Many Turán exponents via subdivisions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 21 July 2022, pp. 134-150
-
- Article
- Export citation
-
Given a graph
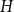 $H$ and a positive integer
$H$ and a positive integer  $n$, the Turán number
$n$, the Turán number 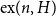 $\mathrm{ex}(n,H)$ is the maximum number of edges in an
$\mathrm{ex}(n,H)$ is the maximum number of edges in an  $n$-vertex graph that does not contain
$n$-vertex graph that does not contain 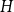 $H$ as a subgraph. A real number
$H$ as a subgraph. A real number 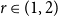 $r\in (1,2)$ is called a Turán exponent if there exists a bipartite graph
$r\in (1,2)$ is called a Turán exponent if there exists a bipartite graph 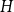 $H$ such that
$H$ such that 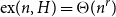 $\mathrm{ex}(n,H)=\Theta (n^r)$. A long-standing conjecture of Erdős and Simonovits states that
$\mathrm{ex}(n,H)=\Theta (n^r)$. A long-standing conjecture of Erdős and Simonovits states that 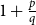 $1+\frac{p}{q}$ is a Turán exponent for all positive integers
$1+\frac{p}{q}$ is a Turán exponent for all positive integers 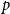 $p$ and
$p$ and 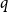 $q$ with
$q$ with 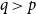 $q\gt p$.
$q\gt p$.In this paper, we show that
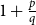 $1+\frac{p}{q}$ is a Turán exponent for all positive integers
$1+\frac{p}{q}$ is a Turán exponent for all positive integers 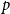 $p$ and
$p$ and 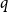 $q$ with
$q$ with 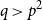 $q \gt p^{2}$. Our result also addresses a conjecture of Janzer [18].
$q \gt p^{2}$. Our result also addresses a conjecture of Janzer [18].
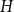

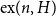

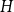
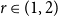
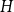
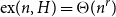
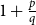
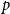
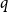
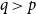
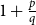
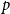
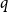
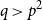
A note on the polynomial ergodicity of the one-dimensional Zig-Zag process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 18 July 2022, pp. 895-903
- Print publication:
- September 2022
-
- Article
- Export citation
Where are the zeroes of a random p-adic polynomial?
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 18 July 2022, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the distribution of the roots of a random p-adic polynomial in an algebraic closure of
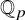 ${\mathbb Q}_p$. We prove that the mean number of roots generating a fixed finite extension K of
${\mathbb Q}_p$. We prove that the mean number of roots generating a fixed finite extension K of 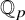 ${\mathbb Q}_p$ depends mostly on the discriminant of K, an extension containing fewer roots when it becomes more ramified. We prove further that for any positive integer r, a random p-adic polynomial of sufficiently large degree has about r roots on average in extensions of degree at most r.
${\mathbb Q}_p$ depends mostly on the discriminant of K, an extension containing fewer roots when it becomes more ramified. We prove further that for any positive integer r, a random p-adic polynomial of sufficiently large degree has about r roots on average in extensions of degree at most r.Beyond the mean, we also study higher moments and correlations between the number of roots in two given subsets of
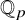 ${\mathbb Q}_p$ (or, more generally, of a finite extension of
${\mathbb Q}_p$ (or, more generally, of a finite extension of 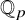 ${\mathbb Q}_p$). In this perspective, we notably establish results highlighting that the roots tend to repel each other and quantify this phenomenon.
${\mathbb Q}_p$). In this perspective, we notably establish results highlighting that the roots tend to repel each other and quantify this phenomenon.
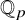
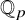
EVALUATING THE TAIL RISK OF MULTIVARIATE AGGREGATE LOSSES
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 15 July 2022, pp. 921-952
- Print publication:
- September 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
New lower bounds for van der Waerden numbers
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 10 / 2022
- Published online by Cambridge University Press:
- 13 July 2022, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that there is a red-blue colouring of
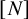 $[N]$ with no blue 3-term arithmetic progression and no red arithmetic progression of length
$[N]$ with no blue 3-term arithmetic progression and no red arithmetic progression of length 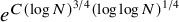 $e^{C(\log N)^{3/4}(\log \log N)^{1/4}}$. Consequently, the two-colour van der Waerden number
$e^{C(\log N)^{3/4}(\log \log N)^{1/4}}$. Consequently, the two-colour van der Waerden number 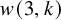 $w(3,k)$ is bounded below by
$w(3,k)$ is bounded below by 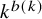 $k^{b(k)}$, where
$k^{b(k)}$, where 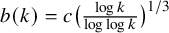 $b(k) = c \big ( \frac {\log k}{\log \log k} \big )^{1/3}$. Previously it had been speculated, supported by data, that
$b(k) = c \big ( \frac {\log k}{\log \log k} \big )^{1/3}$. Previously it had been speculated, supported by data, that 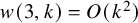 $w(3,k) = O(k^2)$.
$w(3,k) = O(k^2)$.
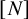
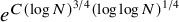
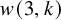
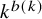
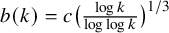
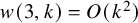
An extended class of univariate and multivariate generalized Pólya processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 11 July 2022, pp. 974-997
- Print publication:
- September 2022
-
- Article
- Export citation
Quadratic Klein-Gordon equations with a potential in one dimension
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 10 / 2022
- Published online by Cambridge University Press:
- 11 July 2022, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper proposes a fairly general new point of view on the question of asymptotic stability of (topological) solitons. Our approach is based on the use of the distorted Fourier transform at the nonlinear level; it does not rely only on Strichartz or virial estimates and is therefore able to treat low-power nonlinearities (hence also nonlocalised solitons) and capture the global (in space and time) behaviour of solutions.
More specifically, we consider quadratic nonlinear Klein-Gordon equations with a regular and decaying potential in one space dimension. Additional assumptions are made so that the distorted Fourier transform of the solution vanishes at zero frequency. Assuming also that the associated Schrödinger operator has no negative eigenvalues, we obtain global-in-time bounds, including sharp pointwise decay and modified asymptotics, for small solutions.
These results have some direct applications to the asymptotic stability of (topological) solitons, as well as several other potential applications to a variety of related problems. For instance, we obtain full asymptotic stability of kinks with respect to odd perturbations for the double sine-Gordon problem (in an appropriate range of the deformation parameter). For the
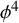 $\phi ^4$ problem, we obtain asymptotic stability for small odd solutions, provided the nonlinearity is projected on the continuous spectrum. Our results also go beyond these examples since our framework allows for the presence of a fully coherent phenomenon (a space-time resonance) at the level of quadratic interactions, which creates a degeneracy in distorted Fourier space. We devise a suitable framework that incorporates this and use multilinear harmonic analysis in the distorted setting to control all nonlinear interactions.
$\phi ^4$ problem, we obtain asymptotic stability for small odd solutions, provided the nonlinearity is projected on the continuous spectrum. Our results also go beyond these examples since our framework allows for the presence of a fully coherent phenomenon (a space-time resonance) at the level of quadratic interactions, which creates a degeneracy in distorted Fourier space. We devise a suitable framework that incorporates this and use multilinear harmonic analysis in the distorted setting to control all nonlinear interactions.
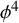
Large-time behaviour and the second eigenvalue problem for finite-state mean-field interacting particle systems
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 08 July 2022, pp. 85-125
- Print publication:
- March 2023
-
- Article
- Export citation
-
This article examines large-time behaviour of finite-state mean-field interacting particle systems. Our first main result is a sharp estimate (in the exponential scale) of the time required for convergence of the empirical measure process of the N-particle system to its invariant measure; we show that when time is of the order
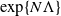 $\exp\{N\Lambda\}$ for a suitable constant
$\exp\{N\Lambda\}$ for a suitable constant 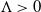 $\Lambda > 0$, the process has mixed well and it is close to its invariant measure. We then obtain large-N asymptotics of the second-largest eigenvalue of the generator associated with the empirical measure process when it is reversible with respect to its invariant measure. We show that its absolute value scales as
$\Lambda > 0$, the process has mixed well and it is close to its invariant measure. We then obtain large-N asymptotics of the second-largest eigenvalue of the generator associated with the empirical measure process when it is reversible with respect to its invariant measure. We show that its absolute value scales as 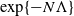 $\exp\{{-}N\Lambda\}$. The main tools used in establishing our results are the large deviation properties of the empirical measure process from its large-N limit. As an application of the study of large-time behaviour, we also show convergence of the empirical measure of the system of particles to a global minimum of a certain ‘entropy’ function when particles are added over time in a controlled fashion. The controlled addition of particles is analogous to the cooling schedule associated with the search for a global minimum of a function using the simulated annealing algorithm.
$\exp\{{-}N\Lambda\}$. The main tools used in establishing our results are the large deviation properties of the empirical measure process from its large-N limit. As an application of the study of large-time behaviour, we also show convergence of the empirical measure of the system of particles to a global minimum of a certain ‘entropy’ function when particles are added over time in a controlled fashion. The controlled addition of particles is analogous to the cooling schedule associated with the search for a global minimum of a function using the simulated annealing algorithm.
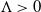
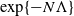
Scalable algorithms for physics-informed neural and graph networks
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 29 June 2022, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generating weighted and thresholded gene coexpression networks using signed distance correlation
-
- Journal:
- Network Science / Volume 10 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 16 June 2022, pp. 131-145
-
- Article
- Export citation
MORTALITY CREDITS WITHIN LARGE SURVIVOR FUNDS
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 15 June 2022, pp. 813-834
- Print publication:
- September 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Universal Digital Twin: Integration of national-scale energy systems and climate data
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 13 June 2022, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bringing network science to primary school
-
- Journal:
- Network Science / Volume 10 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 30 May 2022, pp. 207-213
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fatty acid composition of milk from mothers giving birth at extremely low gestation in Sweden
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 24 February 2022, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Three-dimensional complex architectures observed in shock processed amino acid mixtures
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 09 February 2022, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI: Coming of age?
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 19 January 2022, pp. 1-5
-
- Article
-
- You have access
- HTML
- Export citation
Modelling random vectors of dependent risks with different elliptical components
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 22 February 2021, pp. 6-24
-
- Article
- Export citation
