Refine listing
Actions for selected content:
1854 results in 60Gxx
Random walks in a time-inhomogeneous random environment conditioned to stay positive
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 24 February 2026, pp. 1-13
-
- Article
- Export citation
Total variation distance between SDEs with stable noise and Brownian motion
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 23 February 2026, pp. 1-19
-
- Article
- Export citation
-
We consider d-dimensional stochastic differential equations (SDEs) of the form
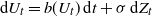 $\textrm{d}U_t = b(U_t)\,\textrm{d}t + \sigma\,\textrm{d}Z_t$. Let
$\textrm{d}U_t = b(U_t)\,\textrm{d}t + \sigma\,\textrm{d}Z_t$. Let 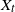 $X_t$ denote the solution if the driving noise
$X_t$ denote the solution if the driving noise 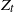 $Z_t$ is a d-dimensional rotationally symmetric
$Z_t$ is a d-dimensional rotationally symmetric  $\alpha$-stable process (
$\alpha$-stable process (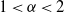 $1\lt \alpha\lt 2$), and let
$1\lt \alpha\lt 2$), and let 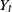 $Y_t$ be the solution if the driving noise is a d-dimensional Brownian motion. Continuing the work started in Deng et al. (2025), we derive an estimate of the total variation distance
$Y_t$ be the solution if the driving noise is a d-dimensional Brownian motion. Continuing the work started in Deng et al. (2025), we derive an estimate of the total variation distance 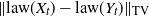 $\|\textrm{law}(X_{t})-\textrm{law}(Y_{t})\|_\textrm{TV}$ for all
$\|\textrm{law}(X_{t})-\textrm{law}(Y_{t})\|_\textrm{TV}$ for all 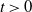 $t \gt 0$, and we show that the ergodic measures
$t \gt 0$, and we show that the ergodic measures 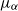 $\mu_\alpha$ and
$\mu_\alpha$ and 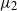 $\mu_2$ of
$\mu_2$ of 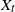 $X_t$ and
$X_t$ and 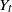 $Y_t$, respectively, satisfy
$Y_t$, respectively, satisfy 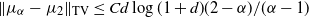 $\|\mu_\alpha-\mu_2\|_\textrm{TV} \leq {Cd\log(1+d)}(2-\alpha)/({\alpha-1})$. We show that this bound is optimal with respect to
$\|\mu_\alpha-\mu_2\|_\textrm{TV} \leq {Cd\log(1+d)}(2-\alpha)/({\alpha-1})$. We show that this bound is optimal with respect to  $\alpha$ by an Ornstein–Uhlenbeck SDE. Combining this bound with a recent interpolation result from Huang et al. (2023), we can derive a bound in the Wasserstein-p distance (
$\alpha$ by an Ornstein–Uhlenbeck SDE. Combining this bound with a recent interpolation result from Huang et al. (2023), we can derive a bound in the Wasserstein-p distance (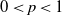 $0 \lt p \lt 1$):
$0 \lt p \lt 1$): 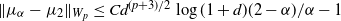 $\|\mu_\alpha-\mu_2\|_{W_p} \leq {Cd^{(p+3)/2}\log(1+d)}(2-\alpha)/{\alpha-1}$.
$\|\mu_\alpha-\mu_2\|_{W_p} \leq {Cd^{(p+3)/2}\log(1+d)}(2-\alpha)/{\alpha-1}$.
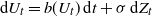
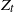

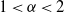
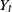
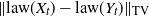
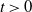
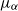
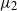
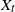
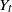
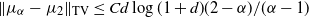

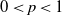
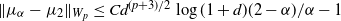
General drawdown-based exit identities for Lévy processes observed at poisson arrival time
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 17 February 2026, pp. 1-52
-
- Article
- Export citation
Fluid limit of a distributed ledger model with random delay
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 13 February 2026, pp. 1-41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bivariate shock models driven by the geometric counting process
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 12 February 2026, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Graphical sequences and plane trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 05 February 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Balister, the second author, Groenland, Johnston, and Scott recently showed that there are asymptotically
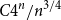 $C4^n/n^{3/4}$ many unordered sequences that occur as degree sequences of graphs with
$C4^n/n^{3/4}$ many unordered sequences that occur as degree sequences of graphs with  $n$ vertices. Combining limit theory for infinitely divisible distributions with a new connection between a class of random walk trajectories and a subset counting formula from additive number theory, we describe
$n$ vertices. Combining limit theory for infinitely divisible distributions with a new connection between a class of random walk trajectories and a subset counting formula from additive number theory, we describe 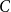 $C$ in terms of Walkup’s number of rooted plane trees. The bijection is related to an instance of the Lévy–Khintchine formula. Our main result complements a result of Stanley, that ordered graphical sequences are related to quasi-forests.
$C$ in terms of Walkup’s number of rooted plane trees. The bijection is related to an instance of the Lévy–Khintchine formula. Our main result complements a result of Stanley, that ordered graphical sequences are related to quasi-forests.

Euler–Maruyama approximation for stable stochastic differential equations with Markovian switching and related asymptotics
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 05 February 2026, pp. 1-29
-
- Article
- Export citation
-
We investigate the EM approximation for
 $\mathbb{R}^d$-valued ergodic stochastic differential equations (SDEs) driven by rotationally invariant
$\mathbb{R}^d$-valued ergodic stochastic differential equations (SDEs) driven by rotationally invariant  $\alpha$-stable processes (
$\alpha$-stable processes ( $\alpha\in(1,2)$) with Markovian switching. The coefficient g violates the dissipative condition for certain states of the switching process. Using the Lindeberg principle, we establish quantitative error bounds between the original process
$\alpha\in(1,2)$) with Markovian switching. The coefficient g violates the dissipative condition for certain states of the switching process. Using the Lindeberg principle, we establish quantitative error bounds between the original process  $(X_t,R_t)_{t\geqslant 0}$ and its Euler–Maruyama (EM) scheme under a specially designed metric. Furthermore, we derive both a central limit theorem and a moderate derivation principle for the empirical measures of both the SDE and its EM scheme. The theoretical results are subsequently validated through a concrete example.
$(X_t,R_t)_{t\geqslant 0}$ and its Euler–Maruyama (EM) scheme under a specially designed metric. Furthermore, we derive both a central limit theorem and a moderate derivation principle for the empirical measures of both the SDE and its EM scheme. The theoretical results are subsequently validated through a concrete example.




Forest fire model on
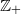 $\mathbb{Z}_+$ with delays
$\mathbb{Z}_+$ with delays
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 February 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a generalization of the forest fire model on
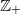 $\mathbb{Z}_+$ with ignition at zero only, studied by Volkov (2009 ALEA 6, 399–414). Unlike that model, we allow delays in the spread of the fires and the non-zero burning time of individual ‘trees’. We obtain some general properties for this model, which cover, among others, the phenomenon of an ‘infinite fire’, not present in the original model.
$\mathbb{Z}_+$ with ignition at zero only, studied by Volkov (2009 ALEA 6, 399–414). Unlike that model, we allow delays in the spread of the fires and the non-zero burning time of individual ‘trees’. We obtain some general properties for this model, which cover, among others, the phenomenon of an ‘infinite fire’, not present in the original model.
The functional discrete-time approximation of marked Hawkes risk processes
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 29 January 2026, pp. 1-42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sub-value and sup-value of a linear diffusion game
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 21 January 2026, pp. 1-48
-
- Article
- Export citation
Multitype branching processes with immigration generated by point processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 12 January 2026, pp. 1-21
-
- Article
- Export citation
Corrections of formulas in ‘An elementary derivation of moments of Hawkes processes’
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 22 December 2025, pp. 1-9
-
- Article
- Export citation
Space-grid approximations of hybrid stochastic differential equations and first-passage properties
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 19 December 2025, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A threshold for Poisson behavior of non-stationary product measures
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems , First View
- Published online by Cambridge University Press:
- 04 December 2025, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
 $\gamma _{n}= O (\log ^{-c}n)$ and let
$\gamma _{n}= O (\log ^{-c}n)$ and let  $\nu $ be the infinite product measure whose nth marginal is Bernoulli
$\nu $ be the infinite product measure whose nth marginal is Bernoulli  $(1/2+\gamma _{n})$. We show that
$(1/2+\gamma _{n})$. We show that  $c=1/2$ is the threshold, above which
$c=1/2$ is the threshold, above which  $\nu $-almost every point is simply Poisson generic in the sense of Peres and Weiss, and below which this can fail. This provides a range in which
$\nu $-almost every point is simply Poisson generic in the sense of Peres and Weiss, and below which this can fail. This provides a range in which  $\nu $ is singular with respect to the uniform product measure, but
$\nu $ is singular with respect to the uniform product measure, but  $\nu $-almost every point is simply Poisson generic.
$\nu $-almost every point is simply Poisson generic.







Ageing and mortality of persons with HIV: a novel data-driven approach
- Part of
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 28 November 2025, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Pre-averaging fractional processes contaminated by noise, with an application to turbulence
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 21 November 2025, pp. 1280-1300
- Print publication:
- December 2025
-
- Article
- Export citation
-
We consider the problem of estimating fractional processes based on noisy high-frequency data. Generalizing the idea of pre-averaging to a fractional setting, we exhibit a sequence of consistent estimators for the unknown parameters of interest by proving a law of large numbers for associated variation functionals. In contrast to the semimartingale setting, the optimal window size for pre-averaging depends on the unknown roughness parameter of the underlying process. We evaluate the performance of our estimators in a simulation study and use them to empirically verify Kolmogorov’s
 $2/3$-law in turbulence data contaminated by instrument noise.
$2/3$-law in turbulence data contaminated by instrument noise.

The distribution of the minimum observation until a stopping time, with an application to the minimal spacing in a Renewal process
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 21 November 2025, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
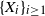 $\{X_{i}\}_{i\geq1}$ be a sequence of independent and identically distributed random variables and
$\{X_{i}\}_{i\geq1}$ be a sequence of independent and identically distributed random variables and 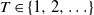 $T\in\{1,2,\ldots\}$ a stopping time associated with this sequence. In this paper, the distribution of the minimum observation,
$T\in\{1,2,\ldots\}$ a stopping time associated with this sequence. In this paper, the distribution of the minimum observation, 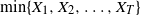 $\min\{X_{1},X_{2},\ldots,X_{T}\}$, until the stopping time T is provided by proposing a methodology based on an appropriate change of the initial probability measure of the probability space to a truncated (shifted) one on the
$\min\{X_{1},X_{2},\ldots,X_{T}\}$, until the stopping time T is provided by proposing a methodology based on an appropriate change of the initial probability measure of the probability space to a truncated (shifted) one on the 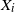 $X_{i}$. As an application of the aforementioned general result, the random variables
$X_{i}$. As an application of the aforementioned general result, the random variables 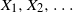 $X_{1},X_{2},\ldots$ are considered to be the interarrival times (spacings) between successive appearances of events in a renewal counting process
$X_{1},X_{2},\ldots$ are considered to be the interarrival times (spacings) between successive appearances of events in a renewal counting process 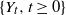 $\{Y_{t},t\geq0\}$, while the stopping time T is set to be the number of summands until the sum of the
$\{Y_{t},t\geq0\}$, while the stopping time T is set to be the number of summands until the sum of the 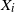 $X_{i}$ exceeds t for the first time, i.e.
$X_{i}$ exceeds t for the first time, i.e. 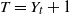 $T=Y_{t}+1$. Under this setup, the distribution of the minimal spacing,
$T=Y_{t}+1$. Under this setup, the distribution of the minimal spacing, 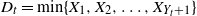 $D_{t}=\min\{X_{1},X_{2},\ldots,X_{Y_{t}+1}\}$, that starts in the interval [0, t] is investigated and a stochastic ordering relation for
$D_{t}=\min\{X_{1},X_{2},\ldots,X_{Y_{t}+1}\}$, that starts in the interval [0, t] is investigated and a stochastic ordering relation for 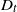 $D_{t}$ is obtained. In addition, bounds for the tail probability of
$D_{t}$ is obtained. In addition, bounds for the tail probability of 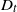 $D_{t}$ are provided when the interarrival times have the increasing failure rate / decreasing failure rate property. In the special case of a Poisson process, an exact formula, as well as closed-form bounds and an asymptotic result, are derived for the tail probability of
$D_{t}$ are provided when the interarrival times have the increasing failure rate / decreasing failure rate property. In the special case of a Poisson process, an exact formula, as well as closed-form bounds and an asymptotic result, are derived for the tail probability of 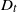 $D_{t}$. Furthermore, for renewal processes with Erlang and uniformly distributed interarrival times, exact and approximation formulae for the tail probability of
$D_{t}$. Furthermore, for renewal processes with Erlang and uniformly distributed interarrival times, exact and approximation formulae for the tail probability of 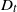 $D_{t}$ are also proposed. Finally, numerical examples are presented to illustrate the aforementioned exact and asymptotic results, and practical applications are briefly discussed.
$D_{t}$ are also proposed. Finally, numerical examples are presented to illustrate the aforementioned exact and asymptotic results, and practical applications are briefly discussed.
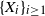
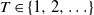
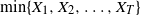
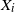
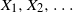
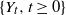
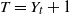
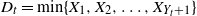
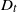
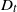
Scaling limits for supercritical nearly unstable Hawkes processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 19 November 2025, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate the asymptotic behavior of nearly unstable Hawkes processes whose regression kernel has
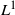 $L^1$ norm strictly greater than 1 and close to 1 as time goes to infinity. We find that the scaling size determines the scaling behavior of the processes as in Jaisson and Rosenbaum (2015). Specifically, after a suitable rescale of
$L^1$ norm strictly greater than 1 and close to 1 as time goes to infinity. We find that the scaling size determines the scaling behavior of the processes as in Jaisson and Rosenbaum (2015). Specifically, after a suitable rescale of 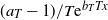 $({a_T-1})/{T{\textrm{e}}^{b_TTx}}$, the limit of the sequence of Hawkes processes is deterministic. Also, with another appropriate rescaling of
$({a_T-1})/{T{\textrm{e}}^{b_TTx}}$, the limit of the sequence of Hawkes processes is deterministic. Also, with another appropriate rescaling of 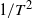 $1/T^2$, the sequence converges in law to an integrated Cox–Ingersoll–Ross-like process. This theoretical result may apply to model the recent COVID-19 outbreak in epidemiology and phenomena in social networks.
$1/T^2$, the sequence converges in law to an integrated Cox–Ingersoll–Ross-like process. This theoretical result may apply to model the recent COVID-19 outbreak in epidemiology and phenomena in social networks.
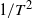
Inhomogeneous random graphs with infinite-mean fitness variables
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 14 November 2025, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider an inhomogeneous Erdős–Rényi random graph ensemble with exponentially decaying random disconnection probabilities determined by an independent and identically distributed field of variables with heavy tails and infinite mean associated with the vertices of the graph. This model was recently investigated in the physics literature (Garuccio, Lalli, and Garlaschelli 2023) as a scale-invariant random graph within the context of network renormalization. From a mathematical perspective, the model fits in the class of scale-free inhomogeneous random graphs whose asymptotic geometrical features have recently attracted interest. While for this type of graph several results are known when the underlying vertex variables have finite mean and variance, here instead we consider the case of one-sided stable variables with necessarily infinite mean. To simplify our analysis, we assume that the variables are sampled from a Pareto distribution with parameter
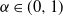 $\alpha\in(0,1)$. We start by characterizing the asymptotic distributions of the typical degrees and some related observables. In particular, we show that the degree of a vertex converges in distribution, after proper scaling, to a mixed Poisson law. We then show that correlations among degrees of different vertices are asymptotically non-vanishing, but at the same time a form of asymptotic tail independence is found when looking at the behavior of the joint Laplace transform around zero. Moreover, we present some findings concerning the asymptotic density of wedges and triangles, and show a cross-over for the existence of dust (i.e. disconnected vertices).
$\alpha\in(0,1)$. We start by characterizing the asymptotic distributions of the typical degrees and some related observables. In particular, we show that the degree of a vertex converges in distribution, after proper scaling, to a mixed Poisson law. We then show that correlations among degrees of different vertices are asymptotically non-vanishing, but at the same time a form of asymptotic tail independence is found when looking at the behavior of the joint Laplace transform around zero. Moreover, we present some findings concerning the asymptotic density of wedges and triangles, and show a cross-over for the existence of dust (i.e. disconnected vertices).
(Empirical) Gramian-based dimension reduction for stochastic differential equations driven by fractional Brownian motion
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 07 November 2025, pp. 1-32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we investigate large-scale linear systems driven by a fractional Brownian motion (fBm) with Hurst parameter
 $H\in [1/2, 1)$. We interpret these equations either in the sense of Young (
$H\in [1/2, 1)$. We interpret these equations either in the sense of Young ( $H>1/2$) or Stratonovich (
$H>1/2$) or Stratonovich ( $H=1/2$). In particular, fractional Young differential equations are well suited to modeling real-world phenomena as they capture memory effects, unlike other frameworks. Although it is very complex to solve them in high dimensions, model reduction schemes for Young or Stratonovich settings have not yet been much studied. To address this gap, we analyze important features of fundamental solutions associated with the underlying systems. We prove a weak type of semigroup property which is the foundation of studying system Gramians. From the Gramians introduced, a dominant subspace can be identified, which is shown in this paper as well. The difficulty for fractional drivers with
$H=1/2$). In particular, fractional Young differential equations are well suited to modeling real-world phenomena as they capture memory effects, unlike other frameworks. Although it is very complex to solve them in high dimensions, model reduction schemes for Young or Stratonovich settings have not yet been much studied. To address this gap, we analyze important features of fundamental solutions associated with the underlying systems. We prove a weak type of semigroup property which is the foundation of studying system Gramians. From the Gramians introduced, a dominant subspace can be identified, which is shown in this paper as well. The difficulty for fractional drivers with  $H>1/2$ is that there is no link between the corresponding Gramians and algebraic equations, making the computation very difficult. Therefore we further propose empirical Gramians that can be learned from simulation data. Subsequently, we introduce projection-based reduced-order models using the dominant subspace information. We point out that such projections are not always optimal for Stratonovich equations, as stability might not be preserved and since the error might be larger than expected. Therefore an improved reduced-order model is proposed for
$H>1/2$ is that there is no link between the corresponding Gramians and algebraic equations, making the computation very difficult. Therefore we further propose empirical Gramians that can be learned from simulation data. Subsequently, we introduce projection-based reduced-order models using the dominant subspace information. We point out that such projections are not always optimal for Stratonovich equations, as stability might not be preserved and since the error might be larger than expected. Therefore an improved reduced-order model is proposed for  $H=1/2$. We validate our techniques conducting numerical experiments on some large-scale stochastic differential equations driven by fBm resulting from spatial discretizations of fractional stochastic PDEs. Overall, our study provides useful insights into the applicability and effectiveness of reduced-order methods for stochastic systems with fractional noise, which can potentially aid in the development of more efficient computational strategies for practical applications.
$H=1/2$. We validate our techniques conducting numerical experiments on some large-scale stochastic differential equations driven by fBm resulting from spatial discretizations of fractional stochastic PDEs. Overall, our study provides useful insights into the applicability and effectiveness of reduced-order methods for stochastic systems with fractional noise, which can potentially aid in the development of more efficient computational strategies for practical applications.





