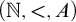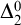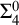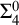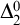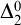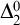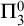Refine listing
Actions for selected content:
130 results in 68Qxx
The random
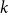 $\textit{k}$-SAT Gibbs uniqueness threshold revisited
$\textit{k}$-SAT Gibbs uniqueness threshold revisited
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove that for any
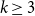 $k\geq 3$ for clause/variable ratios up to the Gibbs uniqueness threshold of the corresponding Galton-Watson tree, the number of satisfying assignments of random
$k\geq 3$ for clause/variable ratios up to the Gibbs uniqueness threshold of the corresponding Galton-Watson tree, the number of satisfying assignments of random 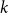 $k$-SAT formulas is given by the ‘replica symmetric solution’ predicted by physics methods [Monasson, Zecchina: Phys. Rev. Lett. 76 (1996)]. Furthermore, while the Gibbs uniqueness threshold is still not known precisely for any
$k$-SAT formulas is given by the ‘replica symmetric solution’ predicted by physics methods [Monasson, Zecchina: Phys. Rev. Lett. 76 (1996)]. Furthermore, while the Gibbs uniqueness threshold is still not known precisely for any 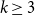 $k\geq 3$, we derive new lower bounds on this threshold that improve over prior work [Montanari and Shah: SODA (2007)]. The improvement is significant particularly for small
$k\geq 3$, we derive new lower bounds on this threshold that improve over prior work [Montanari and Shah: SODA (2007)]. The improvement is significant particularly for small 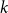 $k$.
$k$.
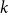
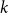
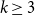
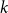
Trace reconstruction of matrices and hypermatrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 10 March 2026, pp. 1-19
-
- Article
- Export citation
-
A trace of a sequence is generated by deleting each bit of the sequence independently with a fixed probability. The well-studied trace reconstruction problem asks how many traces are required to reconstruct an unknown binary sequence with high probability. In this paper, we study the multidimensional version of this problem for matrices and hypermatrices, where a trace is generated by deleting each row/column of the matrix or each slice of the hypermatrix independently with a constant probability. Previously, Krishnamurthy, Mazumdar, McGregor and Pal showed that
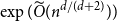 $\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown 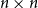 $n\times n$ matrix (for
$n\times n$ matrix (for 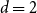 $d=2$) and any unknown
$d=2$) and any unknown 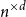 $n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around
$n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around 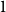 $1$, we improve this upper bound by showing that
$1$, we improve this upper bound by showing that 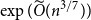 $\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown 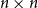 $n\times n$ matrix, and
$n\times n$ matrix, and 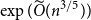 $\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown 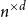 $n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from
$n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from 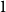 $1$ even as
$1$ even as 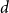 $d$ becomes very large.
$d$ becomes very large.
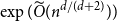
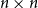
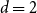
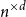
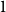
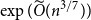
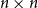
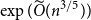
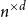
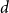
QUANTUM MEASUREMENTS AND ALGORITHMIC RANDOMNESS
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 23 February 2026, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unconditional correctness of recent quantum algorithms for factoring and computing discrete logarithms
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 14 / 2026
- Published online by Cambridge University Press:
- 09 February 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In 1994, Shor introduced his famous quantum algorithm to factor integers and compute discrete logarithms in polynomial time. In 2023, Regev proposed a multidimensional version of Shor’s algorithm that requires far fewer quantum gates. His algorithm relies on a number-theoretic conjecture on the elements in
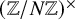 $(\mathbb {Z}/N\mathbb {Z})^{\times }$ that can be written as short products of very small prime numbers. We prove a version of this conjecture using tools from analytic number theory such as zero-density estimates. As a result, we obtain an unconditional proof of correctness of this improved quantum algorithm and of subsequent variants.
$(\mathbb {Z}/N\mathbb {Z})^{\times }$ that can be written as short products of very small prime numbers. We prove a version of this conjecture using tools from analytic number theory such as zero-density estimates. As a result, we obtain an unconditional proof of correctness of this improved quantum algorithm and of subsequent variants.
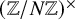
Generalized percolation games on the two-dimensional square lattice and ergodicity of associated probabilistic cellular automata
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 06 February 2026, pp. 1-97
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a highly generalized set-up in which each vertex of the infinite two-dimensional square lattice graph (whose set of vertices is
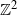 $\mathbb{Z}^{2}$, with each vertex (x, y) adjacent to each of
$\mathbb{Z}^{2}$, with each vertex (x, y) adjacent to each of 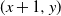 $(x+1,y)$ and
$(x+1,y)$ and 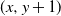 $(x,y+1)$) is assigned, independent of all else, a label that reads trap with probability p, target with probability q, and open with the remaining probability
$(x,y+1)$) is assigned, independent of all else, a label that reads trap with probability p, target with probability q, and open with the remaining probability 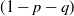 $(1-p-q)$, and, in addition, each edge is assigned, independent of all else, a label that reads trap with probability r and open with probability
$(1-p-q)$, and, in addition, each edge is assigned, independent of all else, a label that reads trap with probability r and open with probability 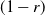 $(1-r)$. This model encompasses the seemingly more general model where, in addition to all the vertex-labels and edge-labels described above, an edge can also be labeled as a target, since assigning the label of target to an edge going from (x, y) to either
$(1-r)$. This model encompasses the seemingly more general model where, in addition to all the vertex-labels and edge-labels described above, an edge can also be labeled as a target, since assigning the label of target to an edge going from (x, y) to either 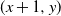 $(x+1,y)$ or
$(x+1,y)$ or 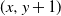 $(x,y+1)$ is equivalent to marking the vertex (x, y) as a trap. A percolation game is played on this random board, involving two players and a token. The players take turns to make moves, where a move involves relocating the token from where it is currently located, say some vertex
$(x,y+1)$ is equivalent to marking the vertex (x, y) as a trap. A percolation game is played on this random board, involving two players and a token. The players take turns to make moves, where a move involves relocating the token from where it is currently located, say some vertex 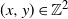 $(x,y) \in \mathbb{Z}^{2}$, to any one of
$(x,y) \in \mathbb{Z}^{2}$, to any one of 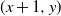 $(x+1,y)$ and
$(x+1,y)$ and 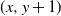 $(x,y+1)$. A player wins if she is able to move the token to a vertex labeled as a target, or force her opponent to either move the token to a vertex labeled as a trap or along an edge labeled as a trap. We seek to find a regime, in terms of values of the parameters p, q, and r, in which the probability of this game resulting in a draw equals 0. We further consider special cases of this game, such as when each edge is assigned, independently, a label that reads trap with probability r, target with probability s, and open with probability
$(x,y+1)$. A player wins if she is able to move the token to a vertex labeled as a target, or force her opponent to either move the token to a vertex labeled as a trap or along an edge labeled as a trap. We seek to find a regime, in terms of values of the parameters p, q, and r, in which the probability of this game resulting in a draw equals 0. We further consider special cases of this game, such as when each edge is assigned, independently, a label that reads trap with probability r, target with probability s, and open with probability 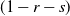 $(1-r-s)$, but the vertices are left unlabeled, and various regimes of values of r and s are explored in which the probability of draw is guaranteed to be 0. We show that the probability of draw in each such game equals 0 if and only if a suitably defined probabilistic cellular automaton (PCA) is ergodic, following which we implement the technique of weight functions or potential functions to investigate the regimes in which said PCA is ergodic. We mention here that one of the main results of Holroyd et al. (2019 Probab. Theory Related Fields 174, 1187–1217) follows as a special case of our main result. Moreover, our result shows that a phase transition happens at the origin (i.e. at
$(1-r-s)$, but the vertices are left unlabeled, and various regimes of values of r and s are explored in which the probability of draw is guaranteed to be 0. We show that the probability of draw in each such game equals 0 if and only if a suitably defined probabilistic cellular automaton (PCA) is ergodic, following which we implement the technique of weight functions or potential functions to investigate the regimes in which said PCA is ergodic. We mention here that one of the main results of Holroyd et al. (2019 Probab. Theory Related Fields 174, 1187–1217) follows as a special case of our main result. Moreover, our result shows that a phase transition happens at the origin (i.e. at 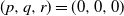 $(p,q,r)=(0,0,0)$ in the case of generalized percolation games, and at
$(p,q,r)=(0,0,0)$ in the case of generalized percolation games, and at 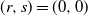 $(r,s)=(0,0)$ in the case of bond percolation games) in the sense that, the probability of draw equals 1 at
$(r,s)=(0,0)$ in the case of bond percolation games) in the sense that, the probability of draw equals 1 at 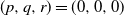 $(p,q,r)=(0,0,0)$ (respectively, at
$(p,q,r)=(0,0,0)$ (respectively, at  $(r,s)=(0,0)$), whereas in every neighborhood around (0, 0, 0) (respectively, (0, 0)), there exists some value of (p, q, r) (respectively, (r, s)) for which the probability of draw equals 0.
$(r,s)=(0,0)$), whereas in every neighborhood around (0, 0, 0) (respectively, (0, 0)), there exists some value of (p, q, r) (respectively, (r, s)) for which the probability of draw equals 0.
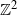
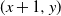
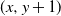
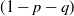
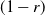
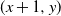
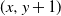
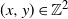
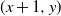
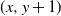
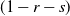
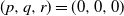
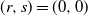
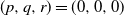

Uniform convergence of adversarially robust classifiers
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 37 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 24 November 2025, pp. 43-72
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In recent years, there has been significant interest in the effect of different types of adversarial perturbations in data classification problems. Many of these models incorporate the adversarial power, which is an important parameter with an associated trade-off between accuracy and robustness. This work considers a general framework for adversarially perturbed classification problems, in a large data or population-level limit. In such a regime, we demonstrate that as adversarial strength goes to zero that optimal classifiers converge to the Bayes classifier in the Hausdorff distance. This significantly strengthens previous results, which generally focus on
 $L^1$-type convergence. The main argument relies upon direct geometric comparisons and is inspired by techniques from geometric measure theory.
$L^1$-type convergence. The main argument relies upon direct geometric comparisons and is inspired by techniques from geometric measure theory.
On approximating the Potts model with contracting Glauber dynamics
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 07 November 2025, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
EXTENDING THE BARMPALIAS–LEWIS-PYE LIMIT THEOREM TO ALL REALS
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 28 October 2025, pp. 1-34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
By a celebrated result of Kučera and Slaman [5], the Martin-Löf random left-c.e. reals form the highest left-c.e. Solovay degree. Barmpalias and Lewis-Pye [1] strengthened this result by showing that, for all left-c.e. reals
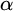 $\alpha $ and
$\alpha $ and 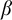 $\beta $ such that
$\beta $ such that 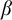 $\beta $ is Martin-Löf random and all left-c.e. approximations
$\beta $ is Martin-Löf random and all left-c.e. approximations 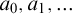 $a_0,a_1,\dots $ and
$a_0,a_1,\dots $ and 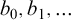 $b_0,b_1,\dots $ of
$b_0,b_1,\dots $ of 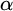 $\alpha $ and
$\alpha $ and 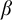 $\beta $, respectively, the limit exists and does not depend on the choice of the left-c.e. approximations to
$\beta $, respectively, the limit exists and does not depend on the choice of the left-c.e. approximations to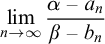 $$ \begin{align*} \lim\limits_{n\to\infty}\frac{\alpha - a_n}{\beta - b_n} \end{align*} $$
$$ \begin{align*} \lim\limits_{n\to\infty}\frac{\alpha - a_n}{\beta - b_n} \end{align*} $$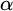 $\alpha $ and
$\alpha $ and 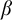 $\beta $.
$\beta $.Here we give an equivalent formulation of the result of Barmpalias and Lewis-Pye in terms of nondecreasing translation functions and generalize their result to the set of all (i.e., not necessarily left-c.e.) reals.
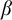
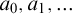
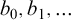
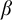
The group of reversible turing machines: subgroups, generators, and computability
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 13 / 2025
- Published online by Cambridge University Press:
- 20 October 2025, e176
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study an abstract group of reversible Turing machines. In our model, each machine is interpreted as a homeomorphism over a space which represents a tape filled with symbols and a head carrying a state. These homeomorphisms can only modify the tape at a bounded distance around the head, change the state, and move the head in a bounded way. We study three natural subgroups arising in this model: the group of finite-state automata, which generalizes the topological full groups studied in topological dynamics and the theory of orbit-equivalence; the group of oblivious Turing machines whose movement is independent of tape contents, which generalizes lamplighter groups and has connections to the study of universal reversible logical gates, and the group of elementary Turing machines, which are the machines which are obtained by composing finite-state automata and oblivious Turing machines.
We show that both the group of oblivious Turing machines and that of elementary Turing machines are finitely generated, while the group of finite-state automata and the group of reversible Turing machines are not. We show that the group of elementary Turing machines has undecidable torsion problem. From this, we also obtain that the group of cellular automata (more generally, the automorphism group of any uncountable one-dimensional sofic subshift) contains a finitely generated subgroup with undecidable torsion problem. We also show that the torsion problem is undecidable for the topological full group of a full
 $\mathbb {Z}^d$-shift on a nontrivial alphabet if and only if
$\mathbb {Z}^d$-shift on a nontrivial alphabet if and only if  $d \geq 2$.
$d \geq 2$.


A note on the computational complexity of weak saturation
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 16 October 2025, pp. 83-88
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove that determining the weak saturation number of a host graph
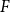 $F$ with respect to a pattern graph
$F$ with respect to a pattern graph 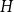 $H$ is computationally hard, even when
$H$ is computationally hard, even when 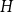 $H$ is the triangle. Our main tool establishes a connection between weak saturation and the shellability of simplicial complexes.
$H$ is the triangle. Our main tool establishes a connection between weak saturation and the shellability of simplicial complexes.
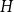
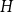
RATE OF CONVERGENCE OF COMPUTABLE PREDICTIONS
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 15 October 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The complexity of intersecting subproducts with subgroups in Cartesian powers
- Part of
-
- Journal:
- Glasgow Mathematical Journal , First View
- Published online by Cambridge University Press:
- 07 October 2025, pp. 1-7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a finite abelian group
 $G$ and
$G$ and  $t\in \mathbb{N}$, there are two natural types of subsets of the Cartesian power
$t\in \mathbb{N}$, there are two natural types of subsets of the Cartesian power  $G^t$; namely, Cartesian powers
$G^t$; namely, Cartesian powers  $S^t$ where
$S^t$ where  $S$ is a subset of
$S$ is a subset of  $G$ and (cosets of) subgroups
$G$ and (cosets of) subgroups  $H$ of
$H$ of  $G^t$. A basic question is whether two such sets intersect. In this paper, we show that this decision problem is NP-complete. Furthermore, for fixed
$G^t$. A basic question is whether two such sets intersect. In this paper, we show that this decision problem is NP-complete. Furthermore, for fixed  $G$ and
$G$ and  $S$, we give a complete classification: we determine conditions for when the problem is NP-complete and show that in all other cases the problem is solvable in polynomial time. These theorems play a key role in the classification of algebraic decision problems in finitely generated rings developed in later work of the author.
$S$, we give a complete classification: we determine conditions for when the problem is NP-complete and show that in all other cases the problem is solvable in polynomial time. These theorems play a key role in the classification of algebraic decision problems in finitely generated rings developed in later work of the author.










Vanishing of Schubert coefficients via the effective Hilbert nullstellensatz
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 13 / 2025
- Published online by Cambridge University Press:
- 01 October 2025, e162
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Schubert Vanishing is a problem of deciding whether Schubert coefficients are zero. Until this work it was open whether this problem is in the polynomial hierarchy
 ${{\mathsf {PH}}}$. We prove this problem is in
${{\mathsf {PH}}}$. We prove this problem is in  ${{\mathsf {AM}}} \cap {{\mathsf {coAM}}}$ assuming the Generalized Riemann Hypothesis (
${{\mathsf {AM}}} \cap {{\mathsf {coAM}}}$ assuming the Generalized Riemann Hypothesis ( $\mathrm{GRH}$), that is, relatively low in
$\mathrm{GRH}$), that is, relatively low in  ${{\mathsf {PH}}}$. Our approach uses Purbhoo’s criterion [57] to construct explicit polynomial systems for the problem. The result follows from a reduction to Parametric Hilbert’s Nullstellensatz, recently analyzed in [2]. We extend our results to all classical types.
${{\mathsf {PH}}}$. Our approach uses Purbhoo’s criterion [57] to construct explicit polynomial systems for the problem. The result follows from a reduction to Parametric Hilbert’s Nullstellensatz, recently analyzed in [2]. We extend our results to all classical types.




Adversarial flows: A gradient flow characterization of adversarial attacks
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 37 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 12 September 2025, pp. 123-179
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A popular method to perform adversarial attacks on neural networks is the so-called fast gradient sign method and its iterative variant. In this paper, we interpret this method as an explicit Euler discretization of a differential inclusion, where we also show convergence of the discretization to the associated gradient flow. To do so, we consider the concept of
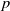 $p$-curves of maximal slope in the case
$p$-curves of maximal slope in the case 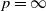 $p=\infty$. We prove existence of
$p=\infty$. We prove existence of 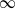 $\infty$-curves of maximum slope and derive an alternative characterization via differential inclusions. Furthermore, we also consider Wasserstein gradient flows for potential energies, where we show that curves in the Wasserstein space can be characterized by a representing measure on the space of curves in the underlying Banach space, which fulfil the differential inclusion. The application of our theory to the finite-dimensional setting is twofold: On the one hand, we show that a whole class of normalized gradient descent methods (in particular, signed gradient descent) converge, up to subsequences, to the flow when sending the step size to zero. On the other hand, in the distributional setting, we show that the inner optimization task of adversarial training objective can be characterized via
$\infty$-curves of maximum slope and derive an alternative characterization via differential inclusions. Furthermore, we also consider Wasserstein gradient flows for potential energies, where we show that curves in the Wasserstein space can be characterized by a representing measure on the space of curves in the underlying Banach space, which fulfil the differential inclusion. The application of our theory to the finite-dimensional setting is twofold: On the one hand, we show that a whole class of normalized gradient descent methods (in particular, signed gradient descent) converge, up to subsequences, to the flow when sending the step size to zero. On the other hand, in the distributional setting, we show that the inner optimization task of adversarial training objective can be characterized via 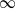 $\infty$-curves of maximum slope on an appropriate optimal transport space.
$\infty$-curves of maximum slope on an appropriate optimal transport space.
Online matching for the multiclass stochastic block model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 21 July 2025, pp. 1360-1381
- Print publication:
- December 2025
-
- Article
- Export citation
MICRO-MACRO PARAREAL, FROM ORDINARY DIFFERENTIAL EQUATIONS TO STOCHASTIC DIFFERENTIAL EQUATIONS AND BACK AGAIN
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 67 / 2025
- Published online by Cambridge University Press:
- 17 March 2025, e13
-
- Article
- Export citation
On the algorithmic descriptive complexity of attractors in topological dynamics
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 45 / Issue 8 / August 2025
- Published online by Cambridge University Press:
- 10 March 2025, pp. 2533-2560
- Print publication:
- August 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A MODULAR BISIMULATION CHARACTERISATION FOR FRAGMENTS OF HYBRID LOGIC
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 31 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 03 March 2025, pp. 590-618
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
There are known characterisations of several fragments of hybrid logic by means of invariance under bisimulations of some kind. The fragments include
 $\{\mathord {\downarrow }, \mathord {@}\}$ with or without nominals (Areces, Blackburn, Marx),
$\{\mathord {\downarrow }, \mathord {@}\}$ with or without nominals (Areces, Blackburn, Marx),  $\mathord {@}$ with or without nominals (ten Cate), and
$\mathord {@}$ with or without nominals (ten Cate), and  $\mathord {\downarrow }$ without nominals (Hodkinson, Tahiri). Some pairs of these characterisations, however, are incompatible with one another. For other fragments of hybrid logic no such characterisations were known so far. We prove a generic bisimulation characterisation theorem for all standard fragments of hybrid logic, in particular for the case with
$\mathord {\downarrow }$ without nominals (Hodkinson, Tahiri). Some pairs of these characterisations, however, are incompatible with one another. For other fragments of hybrid logic no such characterisations were known so far. We prove a generic bisimulation characterisation theorem for all standard fragments of hybrid logic, in particular for the case with  $\mathord {\downarrow }$ and nominals, left open by Hodkinson and Tahiri. Our characterisation is built on a common base and for each feature extension adds a specific condition, so it is modular in an engineering sense.
$\mathord {\downarrow }$ and nominals, left open by Hodkinson and Tahiri. Our characterisation is built on a common base and for each feature extension adds a specific condition, so it is modular in an engineering sense.



LEARNING EQUIVALENCE RELATIONS ON POLISH SPACES
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 03 February 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate natural variations of behaviourally correct learning and explanatory learning—two learning paradigms studied in algorithmic learning theory—that allow us to “learn” equivalence relations on Polish spaces. We give a characterization of the learnable equivalence relations in terms of their Borel complexity and show that the behaviourally correct and explanatory learnable equivalence relations coincide both in uniform and non-uniform versions of learnability and provide a characterization of the learnable equivalence relations in terms of their Borel complexity. We also show that the set of uniformly learnable equivalence relations is
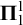 $\boldsymbol {\Pi }^1_1$-complete in the codes and study the learnability of several equivalence relations arising naturally in logic as a case study.
$\boldsymbol {\Pi }^1_1$-complete in the codes and study the learnability of several equivalence relations arising naturally in logic as a case study.
THE COMPLEXITY OF ORDER-COMPUTABLE SETS
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 24 January 2025, pp. 1-24
-
- Article
- Export citation
-
This paper studies the conjecture of Hirschfeldt, Miller, and Podzorov in [13] on the complexity of order-computable sets, where a set A is order-computable if there is a computable copy of the structure
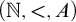 $(\mathbb {N}, <,A)$ in the language of linear orders together with a unary predicate. The class of order-computable sets forms a subclass of
$(\mathbb {N}, <,A)$ in the language of linear orders together with a unary predicate. The class of order-computable sets forms a subclass of 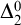 $\Delta ^{0}_{2}$ sets. Firstly, we study the complexity of computably enumerable (c.e.) order-computable sets and prove that the index set of c.e. order-computable sets is
$\Delta ^{0}_{2}$ sets. Firstly, we study the complexity of computably enumerable (c.e.) order-computable sets and prove that the index set of c.e. order-computable sets is 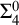 $\Sigma ^{0}_{4}$-complete. Secondly, as a corollary of the main result on c.e. order-computable sets, we obtain that the index set of general order computable sets is
$\Sigma ^{0}_{4}$-complete. Secondly, as a corollary of the main result on c.e. order-computable sets, we obtain that the index set of general order computable sets is 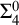 $\Sigma ^{0}_{4}$-complete within the index set of
$\Sigma ^{0}_{4}$-complete within the index set of 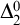 $\Delta ^{0}_{2}$ sets. Finally, we continue to study the complexity of more general
$\Delta ^{0}_{2}$ sets. Finally, we continue to study the complexity of more general 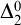 $\Delta ^{0}_{2}$ sets and prove that the index set of
$\Delta ^{0}_{2}$ sets and prove that the index set of 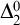 $\Delta ^{0}_{2}$ sets is
$\Delta ^{0}_{2}$ sets is 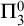 $\Pi ^{0}_{3}$-complete.
$\Pi ^{0}_{3}$-complete.